






















AIの時代において、デジタル変革が加速するなか拡張性、耐障害性、セキュリティの必要性がかつてないほど高まっています。それと同時に、ネットワークのダウンタイム、時間のかかるトラブルシューティング、サイロ化されたアーキテクチャ、手作業による導入の負担が、エンタープライズネットワークの管理をますます困難なものにしています。特に、サイトの拡張、デバイスやアプリケーションの追加、Wi-Fi 6E/7のサポートに対するニーズが急増している場合はなおさらです。 ジュニパーネットワークスのAIネイティブネットワーキングプラットフォームは、エンドユーザーと運用担当者双方のためにクライアントからクラウドまでネットワーク全体で卓越したエクスペリエンスを提供し、新たな業界の基準を打ち立てます。新しいEX4000スイッチシリーズのリリースは、次世代のAIネイティブスイッチングの幕開けです。かつてないほど多くの企業がAIOps、迅速な導入、事前対応型のトラブルシューティング、オープンAPI、Wi-Fi 7サポートを利用できるようになります。 クラウドの比類ない俊敏性と拡張性 EX4000シリーズはマイクロサービスクラウドアーキテクチャを介してJuniper™ Mist AIのクラウドネイティブ基盤上に構築されており、Day 0からDay 2+の運用に俊敏性、効率性、拡張性をもたらします。EX4000のレイヤー2およびレイヤー3の高速な起動時間と、ゼロタッチプロビジョニング(ZTP)、スイッチ設定のテンプレート化などのWired Assuranceによる自動化を組み合わせると、容易な導入、簡素化されたオンボーディング、高速なネットワークアップグレードが実現します。さらに機能を一切妥協することなくJunos® OSの機能をエッジまで拡張しているため、キャンパスおよびブランチへの導入の幅広い多様なユースケースにわたって、業界をリードするAIOpsを活用していただけます。これにより、次のようなことが可能です。 ネットワークサイト全体を容易に導入する 新しいロケーションをシームレスにオンボードする 運用を中断させることなくインフラストラクチャをアップグレードする 迅速に拡張できることは、ジュニパーのAIネイティブネットワーキングプラットフォームの主な差別化要因の1つであり、EX4000はこの領域で有意義なイノベーションを目指すジュニパーの徹底した取り組みを示す一例です。 AIネイティブ運用による卓越したエクスペリエンス:有線SLE、ダイナミックパケットキャプチャ、Marvis デバイスやユーザーのエクスペリエンスについて詳細なインサイトをお求めですか? 効果的にネットワークを最新化し、トラブルシューティングを事前対応で、効率的に行いたいとお考えですか? ジュニパーはWired AssuranceによるAIネイティブの運用により、新しいタイプの事前対応型トラブルシューティングを可能にします。これにより、お客様とIT運用チームは貴重な時間を節約し、大幅なコスト削減を成し遂げ、ユーザーエクスペリエンスに悪影響を及ぼす前に問題を特定して修正できるようになります。ご自身で実際にご確認ください。ここからは、ジュニパーがどのようにしてこれらすべてを実現するのかを詳しく紹介します。 有線SLEによる事前対応型の最適化 比類のない可視化により、有線サービスレベル期待値(SLE)はネットワークのパフォーマンスと信頼性の強化につながります。接続前と接続後のパフォーマンスメトリックが1つのダッシュボードに統合されているため、成功した接続や認証時間をユーザーが簡単に追跡できるほか、スループットを測定し、STPループや接続後のインターフェイスエラーなどの問題を検知できます。異常を事前に特定することにより、リスクがビジネス継続性の妨げとなる前に緩和し、ネットワークの稼働時間とパフォーマンスの信頼性を高めることができます。 ジュニパーのAIネイティブ運用の力をより詳しく知っていただくために、エンタープライズネットワークを管理、運用、拡張する方法に革命をもたらす有線SLEの例をいくつか紹介します。 スイッチの帯域幅SLEにより、混雑ボトルネックをリアルタイムで検知する スループットSLEにより、ネットワークのスループットを監視し、スローダウンを防ぐ DHCP、認証、RADIUS用の分類インサイトにより、トラブルシューティングを簡素化する 高度なスイッチの健全性SLEメトリックにより、リソースの利用を最適化する ダイナミックパケットキャプチャによる迅速なトラブルシューティング

はじめに クラウドネイティブのテクノロジーやKubernetesを企業に導入すると、インフラストラクチャのセキュリティ対策が飛躍的に複雑化します。従来のネットワークセキュリティソリューションでは、コンテナ化された環境というダイナミックな性質に対応するのに苦労することが少なくありません。 課題 東西トラフィックのリスク:マイクロサービスアーキテクチャでは、クラスター内のサービス間の通信(東西トラフィック)が大きなセキュリティリスクとなります。 環境の急速な変化:Kubernetesクラスターはきわめてダイナミックなため、従来のセキュリティ対策を導入、維持することが困難です。 複雑なネットワーク構成:Kubernetesでネットワークセキュリティポリシーを構成するのは容易ではなく、ミスが発生しがちです。 解決策:cSRXおよびSUSE Rancher ジュニパーのcSRXおよびSUSE Rancherを導入すると、こうした課題に効率的に対処しつつ、クラウドネイティブインフラストラクチャのセキュリティを向上できます。 仕組み 1 . cSRXによるマイクロセグメンテーション a. きめ細かい制御:cSRXにより、コンテナレベルできめ細かいセキュリティポリシーを定義しワークロードを分離して、リテラルムーブメントを制限できます。 b. 高度なセキュリティ機能:ファイアウォール、侵入防御、アプリケーションセキュリティなど、包括的なセキュリティサービススイートでアプリケーションを保護します。 c. ダイナミックな対応:cSRXは、Kubernetes環境での変化に自動的に対応するため、継続的な保護が保証されます。 2. SUSE Rancherによる管理の簡素化

ジュニパーのポートフォリオを利用してデータセンターネットワークを構築すれば、コストを削減できます。ジュニパーでは、ジュニパーを採用するか、または他のベンダーにするかを検討されているお客様のために、数多くの財務モデルを作成しています。ジュニパーは確かに、こうしたビジネスケースを常に勝ち取っているというわけではありませんが、おおかたは勝ち取っています。本ブログでは、その理由を説明します。 コスト削減の可能性の概略を理解していただくために、ジュニパーのオンラインデータセンターTCO計算ツールについて少し説明します。これにより、ジュニパーがお客様のために何ができるかについておわかりいただけると思います。より深くご理解いただくには、お客様のデータセンター環境に合わせてカスタマイズされた財務モデルの作成を、ジュニパーの担当アカウントチームにご依頼ください。お客様のデータセンターの運用と経済性を把握するうえで、その詳細な財務モデルを構築する以上に優れた方法はありません。とりわけ、ジュニパーはお客様のために財務モデルを構築し、詳しく説明いたします。財務モデルの構築には、数百社のお客様にサービスを提供してきた当社の長年の経験を活用します。それでは、データセンターネットワークのコストを決める要素それぞれについてご説明します。 CapEx(設備投資) ジュニパーでは、データセンターを運用している会社のコストを、CapEx(設備投資)とOpEx(事業運営費)という2つのカテゴリーに分けています。CapExは非常にシンプルです。お客様にとってのCapExは、スイッチ購入費と、スイッチおよび全ファブリックを管理するために必要なソフトウェア購入費のイニシャルコストです(永続ライセンスは多くの場合CapExと見なされるのに対し、サブスクリプションライセンスはOpExと見なされます。ジュニパーは両方をご用意しています)。実のところ、様々なベンダーがリリースしている数多くのスイッチングハードウェアにおける機能面の差はそれほどありません。エンジニアリングチームと運用チームは、最終的にベンダーを選定し、購買部門に伝えます。購買部門はできる限りコストを削減するためにそのベンダーと値引き交渉します。 ただし、ハードウェアに関して有意な点がジュニパーにはあります。競合他社とは異なり、当社にはシリコンの多様性という戦略があります。スイッチとルーターのジュニパーの包括的ポートフォリオは、Broadcom社のシリコンをベースにしていますが、自社独自のASICの設計も行っています。ジュニパーのPTXラインは、Juniper Expressシリコンがベースで、世界各地の数多くのデータセンターで採用されています。ジュニパーのMXラインは、Juniper Trioシリコンがベースで、WAN(サービスプロバイダの広域通信網)の主力となっています。ただし、MXは多くのデータセンターで利用されているものの、特にDCI(データセンターの相互接続)ユースケースで利用されています。ジュニパーのスイッチのEXラインは、ジュニパーのカスタムシリコンも使用しており、キャンパスおよびブランチ環境でよく利用されていますが、世界各地の数多くのデータセンターでも採用されています。最後に、ジュニパーのQFXポートフォリオはBroadcom社のシリコンがベースです。 ジュニパーの競合他社の多くは、Broadcom社のシリコンまたは自社のカスタムシリコンを全面的に採用しています。ジュニパーがシリコンの多様性に重きを置くということは、戦略レベル(サプライチェーンの選択肢が多い)および戦術レベル(ASICの多彩なポートフォリオで多様なユースケースに対応可能)の両方において、お客様にとって柔軟性があることを意味します。 データセンターネットワークに関するジュニパーの主な差別化要因は、当社のソフトウェアにあり、オンボックスソフトウェア(Junos® OS)とオフボックスソフトウェア(Juniper® Apstra® – データセンターファブリック管理や自動化ソリューション)で構成されています。特に、ジュニパーのソフトウェアの価値は、お客様の運用コストを削減する点にあります。これについては後ほど説明します。 OpEx(事業運営費) OpExは本質的に継続的に発生するコストであり、その算出は、設備投資の算出より少し複雑です。これについて説明しましょう。データセンターを運営するコストは、データセンターのインフラ購入のイニシャルコストに比べかなり高額です。データセンターの機器を新規導入するに先立ち、運用を簡素化することを真剣に検討しないと、大変なことになる可能性があります。 まず、関連するOpEx、特にハードウェアに関連する運用コスト(電力、スペース、冷却)について考えてみましょう。スイッチを設置するにはスペースが必要で、電力も消費しますが、それに加えてオーバーヒートしないように冷却するための追加電力も必要となります。サポートやメンテナンスもまたOpExの要素ですが、ジュニパーでは多くの場合これらの要素を分析から除外しています。ベンダーが異なってもサポートコストに大差ないと考えているためです。 スペースの計算は非常にシンプルです。ジュニパーでは、データセンターの不動産コストの平均を使用しています。平方フィート(または平方メートル)あたりのドル単位(またはユーロ単位など)で表します。スイッチのポートおよび帯域幅の密度は、 お客様がどれだけ必要としているかによって異なります。これにより、スイッチに使用するスペースが決まります。「プラットホームの速度」が高い(つまり、最新の汎用シリコンおよびカスタムシリコンに遅れをとらない)ジュニパーのようなベンダーは、ポート密度の点で優れているため、設置スペースが少なくて済みます。ハードウェアプラットホームのイノベーション競争についていけないベンダーでは、設置スペースを多くとらなければならず、コストが増えます。 環境に優しい持続可能性 環境に優しいということは、コスト削減も意味することが少なくありません。スイッチが直接消費する電力の計算は簡単です。ハードウェアのデータシートで消費電力(ワット数)を確認します。ベンダーを比較する際は、同一条件で比較します。製品の説明書を参照します。ベンダーによっては消費電力の表示方法が異なります。スイッチのベンダーが異なっても同じシリコンを使用していれば、消費電力はほぼ同じはずです。大きく異なっているように見える場合は、データシートの妥当性を疑います。ルーターまたはスイッチの消費電力は最終的に、使用されているASICによって決まるからです。 スイッチを稼働させるための総費用を算出するには、スイッチを動作させるために必要な直接的な電力に加え、スイッチを冷却するために必要な電力も考慮する必要があります。PUE(電力使用効率)は、データセンターのエネルギー効率を評価するために使用する重要な指標です。PUEは、施設の総電力消費量と、IT機器が消費する電力消費量の比率(PUE = 施設の総電力消費量 ÷ IT機器の電力消費量)で表されます。 古いデータセンターのPUEは、1.5を上回ることが少なくありません。新しい最先端のデータセンターのPUEは1.3に近づいています。PUE 1は理論上の最大値です。新しいデータセンターが着工されるごとに、ジュニパーはこの値に徐々に近づいています。つまりPUEが1.5の場合、スイッチの冷却(および照明など、データセンターの他の電力 )に電力が50%余分に必要ということになります。新しい大型のAIトレーニングクラスターの登場により、電力が急速に設計上の制限になりつつあります。液冷といった革新的な技術により、PUEの数値は継続的に下がっていくことでしょう。 電力を消費する製品から直接排出されるのが炭素です。ジュニパーの多くのお客様は、炭素排出量を重視するようになっています。多くの国では、炭素排出量取引プログラムを実施しており、コストが増大する要因(カーボンクレジットの購入)となっていますが、データセンターの運用にとっての新たな収益源(カーボンクレジットの販売)にもなり得ます。 ジュニパーネットワークスの炭素排出量計算ツールの例

ジュニパーは先日、高等教育機関でネットワーキングに携わる革新的なリーダーたちが参加する素晴らしいサミットイベントを開催しました。 このJuniper Networks Global Higher Education Summitでは、業界のリーダーとジュニパーのエキスパートが教育分野におけるデジタル変革に関連する知見、課題、革新的なソリューションを共有できるよう、包括的なプラットフォームを提供しました。 高等教育のITネットワークにおいて、信頼性、シンプルさ、安全な接続性は大学生や教職員へ革新的なサービスとエクスペリエンスを提供する基盤となります。昨今では、ネットワーキングにおけるAIの活用と、それによる教育機関にとっての潜在的なメリットについて関心が大きく高まっています。 依然として残る新型コロナウイルスの影響 今ではコロナ禍は遠い記憶のように感じるかもしれませんが、英国教育機関からの参加者は2人とも、あの日々があったからこそ、ユーザーエクスペリエンスについて新たな視点で考えるようになったと語りました。また、新たな持続可能性の重視など、新しいアプリケーションと要件の変化に関するサポートにおいて、ネットワークインフラストラクチャが革命的な飛躍を遂げたことも振り返っています。 レディング大学の運営責任者ケビン・モーティマー氏は、ITインフラストラクチャ運用管理の体験をお話ししていただきました。ケビン氏は過去のIT投資が不十分だったことによる技術的負債がもたらす課題について率直に認め、「新型コロナウイルス以降の私の仕事は非常に困難なものでした。数多くの技術的負債を引き継いでいましたから」と述べています。 プリマス大学のIT製品開発担当シニアインフラストラクチャアーキテクトであるアレックス・イスラエル氏も自身の見解を語りました。技術インフラストラクチャが持つ広範な効果について「Wi-Fiだけの話ではありません。スタッフ、教職員、学生のネットワークエクスペリエンスについても考えるべきです」と強調しています。この言葉は、インフラストラクチャそのものだけではなく、テクノロジーが全体に与える影響に目を向けることの重要性を示しています。プリマス大学のアレックス氏が「学生たちは照明の改善よりもWi-Fiを求めるだろう」と述べているこちらのビデオをぜひご覧ください(英語)。 ジュニパー製品でデジタル変革が容易に このサミットではキャンパスのアプリケーションについても議論が行われました。例えば、キャンパスの案内や、持続可能性を考慮したHVACシステムとの統合に加え、新しいテクノロジーへの移行時、Ciscoからジュニパーへの移行時に必要なスタッフのスキルセットの見直しと、トレーニングへの投資の必要性も取り上げられています。 特に議論の中心となっていたのは、組織のエクスペリエンス、学生向けアプリケーション、キャンパスのエンゲージメントを強化するためのアプリケーションの変革でした。これにより、すべての関係者にとってよりシームレスで魅力的なエクスペリエンスを提供することを目指して、プロセスの革新とデジタル化を継続して取り組むことが強調されました。 さらに、レガシーネットワークからAIネイティブネットワーキングへの移行についても深く掘り下げ、データを活用して運用とエクスペリエンスの両方を向上させる方法について議論しました。一部の講演者やゲストは、現代の教育におけるニーズに応えるためのネットワークの移行やアップグレードする方法についての知見、これらの変化をどのように乗り切ったかについての実例を交えて共有しました。 テキサス大学ダラス校、最高技術責任者のブライアン・ドーティー氏は、研究を重視する同校がキャンパス内すべての建物を100ギガビットで接続することを目標に、どのようにしてネットワーキングの刷新を始めたかについて語りました。彼のキャンパスではレガシー機器が度々ボトルネックとなり、テクノロジーに精通した学生たちはRedditなどのソーシャルメディアでその不満を訴えていました。 「Juniper Mist™でアップグレードを完了し、アクセスレイヤーを整備すると、それまでソーシャルメディアに投稿されていた学生からの不満などは何も投稿されなくなりました」とドーティー氏は述べています。 Marvisが問題を数分で解決 プリマス大学のアレックスも印象的な逸話を紹介してくれました。彼の大学では、新しい設備を設置するのは夏期休暇など授業が行われない合間であることが多く、彼がチームと協力してキャンパスに新しいプリンターとドアのアクセス装置を設置している際、特定できないエラーに直面していました。しかし、ジュニパーの仮想ネットワークアシスタントMarvis™のサポートで問題を明確にし、特定のサーバーの再起動によって問題が解決できることを突き止めたのです。 「以前なら、この問題を解決するのに何時間もかかっていたと思います」と彼は述べました。「時間が経つにつれて、信頼感はますます高まっています。Mist Cloudのマイクロサービスには非常に満足しています」 頭痛の種から驚きのエクスペリエンスへ ジュニパーの戦略について多くの方から評価をいただけて光栄に思います。Juniper Networks Global Higher Education Summitは、業界の専門家とアイデアを交換し、ベストプラクティスを共有し、高等教育のITインフラストラクチャにおけるイノベーションを促進する、コラボレーションと知見に富むプラットフォームとなりました。
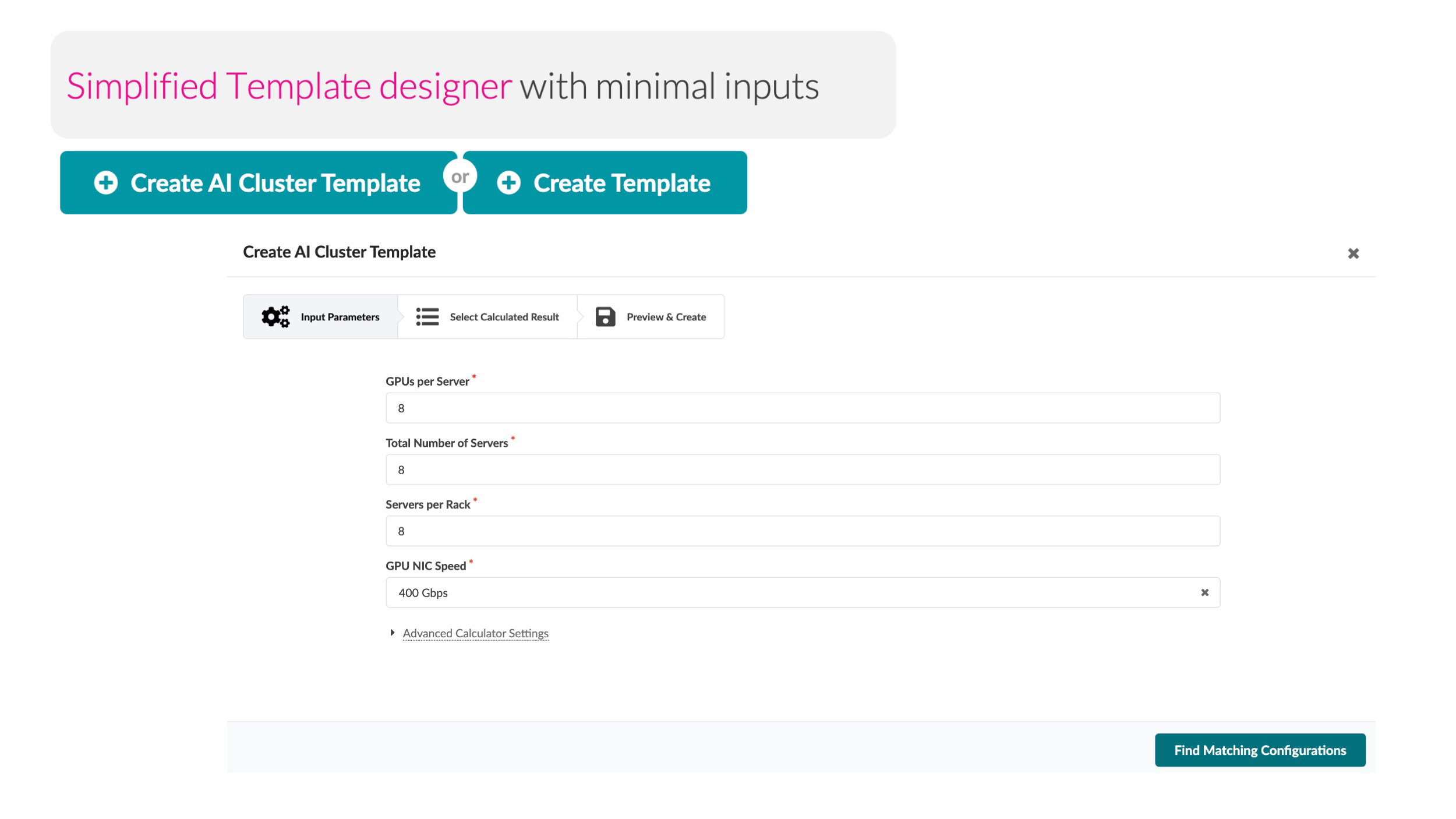
エンタープライズのIT部門は 、人工知能(AI)の最近の進歩を活用するために「とにかく何かをしなければ」というプレッシャーを抱えています。業界を問わず、研究開発の脇役だった生成AIは、現在では役員が重視する必須課題となっています。しかし、ほとんどのエンタープライズのネットワーキングチームは、どこから手をつけるべきかわかっていません。 AIワークロード用の新しいデータセンターを構築する際には、あらゆる種類の新しいテクノロジーや新しいプロトコルに直面することになりますが、実際には、企業の既存のネットワーキングインフラストラクチャや専門知識の多くをそのまま利用できるのです。当社のお客様にこの事実を伝えると、多くの方が驚きの声を上げます。 ジュニパーでは、新しいAIデータセンターアーキテクチャの展開と運用に関連した固有の課題について、お客様をサポートしています。7月には、AIデータセンター(「AIのためのネットワーキング」)ソリューションを立ち上げ、 Juniper™ Apstraデータセンターファブリック管理と自動化ソフトウェアが担う重要な役割について紹介しました。計画的なファブリックなど、複雑で独自のAIデータセンターの実装は不要です。Apstraが、Day 0の設計からDay 1の展開、Day 2以降の継続的な運用まで、AIデータ センターネットワークのライフサイクルの全段階をサポートします。こちらの新しいソリューションブリーフで詳細をご確認ください。 Juniper ApstraテンプレートでAIデータセンターの展開と運用を簡略化 AIの最近の進歩を活用するために、ネットワークチームは新しいAIデータセンター (AI DC)インフラストラクチャの構築を任されています。AIトラフィックパターン(一般に「エレファントフロー」と呼ばれます)に固有の課題と要件に対応するためには、応答性に優れた、将来を見越したネットワーキングおよび管理アプローチが必要です。これまでの一般的なエンタープライズデータセンターとはまったく異なり、高価なGPU(グラフィック処理ユニット)を最大限に活用し、JCT(ジョブ完了時間)を最小化することで、AIデータセンターの経済性を最適化することがきわめて重要となります。 幸い、あらゆるネットワークチームがすでに使い慣れているイーサネットインフラストラクチャを用いて、この課題に対応できます。ただし、AI DCの場合、新しいネットワークアーキテクチャと新しい手法を通じてイーサネットファブリックを調整し、パフォーマンスを最適化する必要があります。Apstraは、新しいAI DCアーキテクチャとファブリック調整の課題の両方を楽々と処理します。AI DCの設計が、既存のApstraの設計図を使用してテンプレートデザイナーで作成されます。またApstraによるAIトレーニングネットワークの自動調整により、これまでの時間がかかる手動アプローチと比較して、時間と手間を大幅に節約できます。これらの新機能は、既存のApstraライセンスにより無料で提供されます。 従来のワークロードとは異なり、AIワークロード用のAI DCファブリックの設計と設定には固有の要件と課題が発生します。ApstraのAIクラスターテンプレートデザイナーを使用すると、具体的なリソース要件とワークロードに合わせて調整された、検証済みで最適化されたApstraテンプレートをすばやく簡単に作成できます。必要なGPU、サーバー、ラックの数など、最小の入力を指定するだけで、カスタマイズされたラックテンプレートがツールによって生成されるため、リソース利用率を効率化して、パフォーマンスの潜在的なボトルネックを最小化し、数回クリックするだけでネットワークを高い信頼性で拡張できます。「レール最適化」設計を知らなくても、Apstraが構築方法を教えてくれます。データ センターネットワークの運用状態がテンプレートで宣言されているインテントと一致していることを確認するために、Apstraが継続的に検証を行います。 Apstra AIクラスターテンプレートデザイナー AIトレーニング環境は、設計の要件が独特で、接続数が多いため、展開が複雑でエラーが起きやすくなります。Apstraの設計図にはケーブルマップが含まれています。このケーブルマップとラックの立面図情報により、データセンター技術者はリンクとエンドポイントの正確なリストに基づいて、高い精度でケーブル配線作業を完了できます。 GPUサーバーのNIC(ネットワークインターフェイスカード)は、AI DC設計において重要な役割を果たします。GPUのNICをAll-to-Allルーティング用に設定するのは労力がかかり、ネットワークファブリック全体の理解が必要です。人工知能や機械学習用のApstraホストエージェントが、GPUネットワーク設計図から取得した正しいIPアドレスとルーティング情報に基づいて、GPUのNICを自動的に設定します。 Apstra GPU/NIC監視 入手困難なGPUの納入を待っている間にAI

2024年はジュニパーにとって、控えめに言っても刺激的な年でした。HPEによる買収(2025年前半の契約締結に向けて進行中)の件はさておき、ジュニパーは絶えずAIネイティブネットワーキングプラットフォームのイノベーションを推進してきました。またエンタープライズ、サービスプロバイダ、クラウドセグメントにわたってジュニパーの市場投入の目標を継続的に実現しています。 ジュニパーが2024年で成し遂げたすべてのことを大変誇りに思います。ジュニパーのキャンパス&ブランチ、データセンター、WANルーティング、セキュリティの各製品は、主要な病院、ホテル、学校、店舗、キャンパス、工場、サービスプロバイダにおいてITの生産性を向上し、ユーザーや運用担当者に優れたエクスペリエンスをもたらす性能を何度も実証しました。 そこで、この機会に、この1年間での成果を振り返るとともに、2025年にお披露目される、さらなるイノベーションについて少しだけお伝えしたいと思います。 キャンパスとブランチの運用の簡素化 IT運用チームは、ますます複雑化するネットワークに対応し続けるために、これまで以上のプレッシャーにさらされています。また、エンドユーザーの期待値は過去最高となっています。ジュニパーのAIOpsはネットワーク管理を簡素化することで、IT運用チームが事後対応型から事前対応型の管理に移行できるようにサポートします。 事前対応型の管理では、ネットワークエクスペリエンスに影響が出る前に問題の発見と修正が可能になり、その結果、エンドユーザーの満足度が向上し、障害対応チケットが最大90%削減できます。AIネイティブインサイトと自動化によって、IT運用チームは障害対応に費やしていた時間から解放されるようになり、より戦略的なビジネスイニシアチブに時間を費やして専念できます。 Mist AI™はジュニパーのAI for Networking機能の基盤となるものです。ジュニパーは市場初の対話型VNA(仮想ネットワークアシスタント)「Marvis」を開発しました。このVNAは自然言語処理を使用して、事前対応型の推奨事項の提供と、自動運転アクションのサポートを行います。Mist AIは、クライアントからクラウドまでのアクティビティを明確に関連付ける機能を持つ初めてのソリューションでもありました。そしてこの1年は、ジュニパーのキャンパスおよびブランチソリューションを以下の機能により強化することで水準を上げ続けてきました。 Marvis® Minisは業界初かつ唯一のデジタルエクスペリエンスツインであり、ユーザーの接続をシミュレーションすることで無線、有線、SD-WANにわたる問題を特定します。Marvis Minisはエンドユーザーがネットワークに接続していなくても問題を発見し修正することができます。 Marvisのアプリケーションエクスペリエンスインサイトは、ZoomやMicrosoft® Teamsの通話品質を事前に予測し、ユーザーが通話に参加する前に潜在的な問題を特定します。こうした事前対応型の機能により、エンドユーザーに影響が及ぶ前にネットワークの潜在的な問題を迅速に解決できます。 新しいMarvis Actionsは、ブラックホールトラフィックを特定するスイッチポートの構成ミス、トラフィックループを報告するAPループ検知、ISP障害が原因でアクセスできないAPを特定するオフラインAPなどの機能により、無線および有線のトラブルシューティングを強化します。 Wi-Fi 7向けAIは、より高速で遅延が少なく信頼性が高い無線ネットワーキングを実現し、ネットワークを次のレベルへ引き上げます。AIドリブンによる自動化とインサイトを活用し、Wi-Fi 7への移行を効率化します。高密度環境のためのシームレスなパフォーマンスを確保するとともに、問題に事前に対処することで優れたユーザーエクスペリエンスを提供します。 AIネイティブの力をデータセンターまで拡大 2024年では、ジュニパーはデータセンター機能一式も新たに導入しました。パフォーマンスの最適化、運用コストの削減、ネットワーク管理の簡素化のために設計されたものです。 例えば、ジュニパーのApstra™自動化ソフトウェアを基に新しいAIネイティブなApstraクラウドサービスを構築しました。このクラウドベースのアプリケーションスイートは、可視化とAIネイティブインサイトを強化することで、アプリケーションエクスペリエンスと影響分析を改善します。こうしたアプリケーションは、受賞歴のあるVNA機能をデータセンターのお客様にも提供するためにリリースされたデータセンター向けMarvis VNAを見事に補完しています。 AIワークロードはこの1年のジュニパーにとって特に注目すべきものでした。「AIのためのネットワーク」でトップに立ち、お客様のAIへの投資対効果を最大化させるために、ジュニパーはOps4AIラボをリリースしました。この革新的なラボでは、ジュニパーのチームだけでなく、お客様もネットワークパフォーマンスのテストや設計の検証ができるほか、イーサネットファブリックのAIトラフィックを最適化するための新しいJVDや機能も提供しています。さらに、ジュニパーは市場初となる800G PTXルーターおよびQFXスイッチをリリース。ワークロードの大小に関係なく、すべてのデータセンターに比類ないパフォーマンスと拡張性をもたらしました。 こうした新しい機能により、ジュニパーは、最も柔軟に設計可能で、最も管理しやすく、最も迅速に導入できるデータセンターネットワークを実現し、提供します。 広域ネットワーキングのための新基準の設定 ジュニパーは、WAN(広域ネットワーキング)を効果的に再定義し、比類ないパフォーマンス、信頼性、簡素化を実現しました。最先端のハードウェアとAIを活用した機能を駆使して、ジュニパーは業界をリードする企業が現在の課題に対応しつつ将来にも備えられるWANを構築できるようにサポートします。以下は、この1年のジュニパーによるWAN関連イノベーションの一部です。 業界屈指の拡張性と効率性を実現した800Gルーター:膨大な帯域幅要件に対応し、最新のアプリケーションや高密度環境向けの優れたパフォーマンスを確保できるように設計されています。
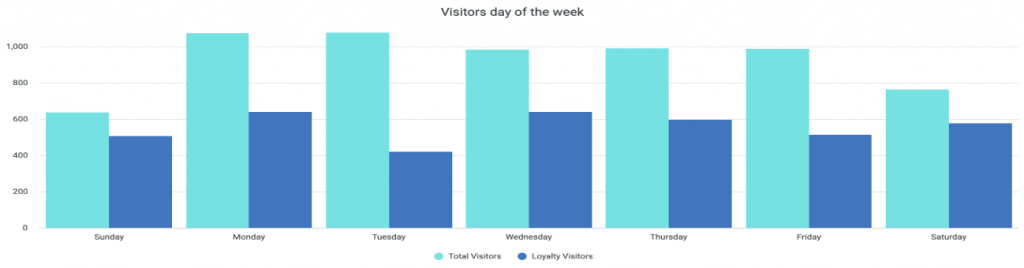
利用者や訪問者のエクスペリエンス向上から競争優位性の獲得や効果的な環境保護の取り組みまで、ファシリティ(施設や設備)の利用と占有率に関するインサイトは、小売店、オフィス、病院、教育機関にとって非常に貴重な情報になります。しかしながら、ファシリティ、不動産、事業の管理者にとって、建物の正確な利用状況を効率的に、他に影響を与えることなく長期にわたって追跡し、実用的なインサイトを得ることは、実際に行うとなると大変な作業になります。 このブログでは、従来のファシリティ管理分析に見られるギャップについて探るとともに、Juniper Mist™の占有分析の独自の機能がどのようにして他に類を見ないインサイトを引き出し、これが建物と敷地の快適性、適切な整備、安全性、効率的な使用を実現するうえでどのように役立つのかをご紹介します。 これまで欠けていたもの 従来のファシリティ管理分析にはいくつかの欠点があり、そのためスペースの利用状況とリソース配分に関するインサイトには限られた価値しかありませんでした。 きめ細かさの不足:ほとんどの分析で提供されるのは概要データのみであり、ファシリティ内の特定のエリアについて情報に基づいた決定を下せるほどの十分な詳細を得られない 静的またはサイロ化されたデータへの依存:静的またはサイロ化されたデータソースが分析に利用されることが多く、スペース利用状況の変化をリアルタイムかつダイナミックに把握することができない 長期トレンドの追跡における柔軟性の欠如:ソリューションは通常、短期的な枠組でしかトレンドを捉えないため、経営者にとっては、パターンを正確に特定して事前対応で長期にわたった計画を立てることが困難 業界を横断しての適応性の限界:多くの分析システムでは、過度に一般化されたインサイトが提供されるため、ヘルスケア、教育、小売業といった業界独自のニーズに対応できない Juniper Mistの占有分析で掘り下げる JuniperのPremium Analyticsサブスクリプションの占有分析およびエンゲージメント分析で提供されるのは、単なる概要データではありません。BLE(Bluetooth® LE)が統合されたジュニパーの強力なWi-Fiアクセスポイントから得られたデータをもとに、ファシリティ内でのユーザーの行動に関する詳細なインサイトが提供されます。 先進技術を活用することで、ジュニパーは従来のソリューションのレベルを超える詳細な分析を提供し、お客様がスペースの利用状況を正確に把握して情報に基づいた意思決定ができるようサポートします。お客様が管理する大規模な企業オフィス、小売店舗、病院、大学キャンパスなど、ジュニパーのデータドリブンの分析により、スペース利用について情報に基づいた決定を下すのに必要な情報と統計が提供されます。これらの情報は次の概念に基づきます。 人流 滞在時間 ゾーン占有率 例えば、小売店の経営者は、買物客の人流の変化を1年を通して追跡し、それに応じて従業員の配置や在庫水準を調整できます。病院であれば、患者の流入出パターンを日ごとに把握し、待ち時間を最適化して患者のエクスペリエンスを向上させることができます。教育機関の場合は、学生が建物、図書館、教室を利用するパターンについてインサイトを得ることで、年間を通して、ピーク期間中のキャンパスと建物の管理を改善できます。 図1. 全訪問者およびロイアリティ訪問者の観測値(日/週/月ごと) 長期にわたる高人流ゾーンおよび滞在時間を把握する 利用者がファシリティ内のどこに最も長く滞在しているかを知ることは、建物のフロアプランとリソース配分について情報に基づいた決定を下すうえで不可欠です。ジュニパーのダッシュボードで、人流が多いゾーンを特定し、滞在時間、または利用者が特定のエリアにいた時間に関するデータを、最長13か月の期間にわたって確認できます。この機能が特に役立つケースとして、小売環境での商品配置の最適化、オフィス環境での照明、HVAC、アラームのプログラミング、病院やオフィスにおける混雑管理と利用者の流れの改善が挙げられます。 図2. ファシリティ内のさまざまなエリアの訪問者/デバイスの滞在時間 Mistの占有分析で得られるインサイトを利用して、組織の意思決定者はレイアウトを調整するか、ユーザーエクスペリエンスの向上を目的とする戦略を実行できます。例えば、サービスやスタッフの配置を最も必要とされるところに変更します。また、小売環境では、買物客が店内の特定のセクションに滞在する時間が長い、特定の場所から別の場所へ何度も移動している、などということがわかるかもしれません。そうであれば、そのスペースをより適切に活用できるようにデザインを見直すことができます。 図3. ファシリティの特定のエリアから別のエリアへ客がどのように移動しているかを表示(数日、数週、数か月単位) 時系列トレンド:パターンを見つけて業務を最適化する さまざまなダッシュボードで時系列の幅(時間/日/月)を変更できるため、行動の変化を時間経過に沿ってモニタリングできます。これらのトレンドからファシリティの利用状況の変化を明らかにすることができ、管理者はニーズを予測して問題になる前に対処できます。オペレーションとファシリティのチームは、暖房、照明、人員レベルを予測される占有率に応じて調節するなど、需要の変化に事前に対応できます。不動産管理チームも、長期にわたるスペースの利用状況を把握して、将来的にポートフォリオに関してより適切な決定を下すことができます。

このブログシリーズの初回では、LLMのトレーニングにおける課題を取り上げました。前回は、AIに投資する企業のLLM消費モデルであるMaker(作成者)、Taker(使用者)、Shaper(形成者)、RAGを確認しました。今回は、AIアプリケーションの導入モデルと、各モデルのコストに関する検討事項について説明します。 AIの導入により、AIデータセンターが大きく成長し、投資が大幅に増加しています。以前はクラウドプロバイダがほぼ独占状態でしたが、現在は企業がプライベートデータセンターを利用して自社のAIデータセンターを拡張し、AIワークロードとアプリケーションの制御を自ら行うようになっています。 AIデータセンターへの投資を最大限に活用する IDCによると、AIデータセンターのスイッチング機器への企業投資が、2027年までに10億米ドルに増加し、年平均成長率が158%になると予測されています。クラウドプロバイダのスイッチングも同期間で年平均成長率91.5%と顕著な増加が続くと見込まれますが、一部の企業は、ハイブリッドクラウド戦略を採用するために、トレーニングや推論のワークロードの一部をプライベートデータセンターへ移す予定です。 生成AIで意味のある結果を引き出すには、モデルで自社データを使用しなければならないとほとんどの企業が気づいています。AIによるデジタル変革は、従業員に業務でパブリックLLMを使用するよう指令を出すように簡単にはいかないのです。 構築と購入:どちらを選ぶか? 自社のプライベートデータセンターを構築する。パブリッククラウドプロバイダからAIサービスを購入する。両方を組み合わせたハイブリッドクラウドモデルを使用する。どれを選択しても結局は大きな問題が立ちはだかります。 データの機密性:扱っている機密データや専有データローカルは、プライベートクラウドに保存する必要がある、もしくはデータの地理的境界を制限するデータ主権ルールの対象になっていませんか? テクノロジー業界や金融業界、政府機関、医療業界のユースケースでは、知的財産を保護するため、あるいは訴訟を避けるためにプライベートデータセンターが必要になる傾向があります。 専門知識:データサイエンスやネットワーキングに関する知識のある従業員はどの程度いますか? 適切な人材を確保している場合は、プライベートデータセンターの展開が強力な選択肢になります。しかし、そうでなければ、社内で専門知識を養うかアウトソーシングしなければなりません。 地理的要因:自社のデータセンターニーズをサポートできる十分なファシリティ(施設や設備)が、必要とされる場所にありますか? GPUあたり700W消費するため、大規模なトレーニングクラスターでは、既存のファシリティにコストのかかる電力のアップグレードが必要になることもあります。あるいは、電力を予算内に抑えるため、AIクラスターをさまざまな場所にあるデータセンターに分散することもできます。RAGなどの推論パフォーマンスにより、AIデータセンターがエッジの方へ移る可能性があります。そうなると、小さなAIクラスターが物理的にユーザーに近づきます。例えば、IoTアプリケーションが製造現場に展開されることになります。また、ハイブリットアーキテクチャでは、トレーニングや推論、RAGのためのAI機能を適切な場所に展開するために、データセンターを構築できる場所では構築し、構築できないが必要な場所では購入することができます。 市場投入期間:市場投入に対する圧力はありますか? 即時の投入を求められているなら、パブリッククラウドサービスです。市場投入期間が短縮され、プライベートデータセンターの導入を計画したりする貴重な時間を確保できます。AIによる変革はどこまで進んでいますか? まだ着手したばかりで、自社での効果を知るために実験を繰り返す必要がある状態ですか? その場合も、パブリッククラウドがお勧めです。しかし、AIに熱心に取り組んでいて、ビジネスのさまざまな分野での使い方を計画している場合は、経済分析によると、一般にプライベートクラウドインフラストラクチャへの投資が推奨されます。 企業戦略:多くのクラウド変革プロジェクトがそうであるように、AIへの取り組みも部門レベルで始まることが多く、特定の顧客や運用上の課題の解決を目的に、独立したAIクラスターがさまざまな場所で作り出されています。企業が、AIインフラストラクチャの統合や共有を進める包括的な企業戦略を立てれば、AIの投資コストの償却効率も上がり、プライベートデータセンターのAI投資を既存の企業予算内に収めることができます。 当初、パブリッククラウドはAIテクノロジーのイノベーターや早期導入者にとって唯一の選択肢でした。依然として大半のAI戦略でパブリッククラウドが重要ではありますが、データのセキュリティやコストに対する懸念から、プライベートデータセンターやハイブリッドクラウドアーキテクチャが主流になりつつあります。ジュニパーのオンラインイベント「Seize the AI Moment(AIでチャンスをつかむ)」では、お客様、パートナー、業界の専門家が独自のハイブリッドクラウドのユースケースや戦略について議論しています。その中では、金融機関のデータセキュリティ問題や、コストとパートナーのバランスを取るためのハイブリッドクラウドを使用した戦略などが話題になりました。 コスト:費用のかかるAIの世界でROIを最大化 どの導入モデルでも、AIの展開に費用がかかることに変わりはありません。AIのコストは、予算、専門知識、時間の観点から計算されますが、いずれの要素もリソースに限りがあります。専門知識と時間のコストは企業によって異なりますが、AIへのハードダラー投資は市場主導で変化し、割り当てられた予算のみが障壁になります。 GPUサーバー1台あたりのコストは、およそ40万ドル。そのため、小規模AIデータセンターのインフラストラクチャコストだけでも数百万ドルになる可能性があります。しかし、希望の光も見えてきました。PyTorch 2.0のようなAIフレームワークが、NVIDIA製チップセットとの緊密な統合や依存を解消したのです。これにより、IntelやAMDなどの競合GPU製品にも扉が開かれ、市場力学が崩壊し、コストの正常化に向かっています。 現状レベルでは、パブリッククラウドプロバイダからAIサービスを購入したほうが、プライベートAIデータセンターを構築するよりコスト効率に優れていると容易に予測できます。一方、ACG Researchの最新の総所有コスト(TCO)分析からは異なる結果が出ています。プライベートAIデータセンターとパブリッククラウドでホストされる同等のAIサービスの3年間のTCOを比較したところ、プライベートデータセンターモデルの方がTCOを46%節約できることがわかりました。この主な原因は、パブリッククラウドサービスに関連する高額な定期コストです。 ACGのレポートでは、AIデータセンターの構築コストについても、InfiniBandとイーサネットのネットワーキングコストを比較して詳しく分析しています。その結果、ジュニパーのイーサネット(RoCE v2)とJuniper

このブログシリーズの初回のブログでは、基盤となる大規模言語モデル(LLM)の開発の複雑さと、開発に必要な膨大なリソースについて取り上げ、多くの企業にとってこの開発が手の届かないものであることを説明しました。今回は、すべての企業がこれらの基盤となるLLMを、自社のプライベートデータセンターで活用できる選択肢を紹介します。 128のGPUを備えた小規模なAIデータセンターであっても、導入には数百万ドルのコストがかかるため、効率性に投資することがコスト抑制の鍵となります。この投資アプローチは、ジュニパーが提唱するAIデータセンターのABC、つまり、アプリケーション(Application)、構築(Build)または購入(Buy)、コスト(Cost)に基づいています。このブログでは、特にアプリケーションのニーズが企業のAI投資におけるAI消費モデルにどのように影響するかについて見ていきます。 アプリケーションの複雑さ AIへの投資を計画する際には、まずAIアプリケーションから期待される目標、目的、成果を理解することが重要です。貴社のユースケースは、カスタマーエクスペリエンスを向上させるためのAIを活用したサポートアシスタント、文書解析ツール、または技術文書アシスタントなど、より汎用的なものでしょうか? それとも、業界や企業特有の、よりカスタマイズされ差別化されたAIアプリケーションでしょうか? カスタマイズのレベルが高くなるほど、すでに複雑な開発プロセスがさらに複雑になり、それが基盤となるLLMやアプリケーションの消費モデルに影響を与えます。 McKinsey Consultingは、AIアプリケーションを導入するための3つのアプローチを、Maker(作成者)、Taker(使用者)、Shaper(形成者)と定義しています。 作成者は業界の大手プレイヤー 作成者は、インターネットデータを元に独自の基盤となるLLMを開発するための財政的手段と専門知識を持つ、世界でごくわずかな企業です。これらの企業には、Google(Gemma、Gemini)、Meta(Llama)、OpenAI(GPT)、Anthropic(Claude)、Mistral(Large、Nemo)、Amazon(Titan)などがあります。LLMの開発が主要な業務ではないほとんどの企業は、使用者または形成者の道を選ぶことになります。 使用者は既存のAIアプリケーションをそのまま活用 汎用的なカスタマーチャットボットや、自然言語処理(NLP)を既存のデータベースに接続するなど、あまり複雑でないサービスを導入する企業は、既製のLLMをカスタマイズする必要はありません。企業は、ライセンス版でもオープンソース版でも、事前にトレーニングされたLLMに基づいた既存のAIアプリケーションを「使用」し、そのモデルを推論のために導入できます。 今日、これらのアプリケーションはほとんどの企業にとって必須の要素となっています。つまり、競争上の差別化はほとんどないかもしれませんが、複雑さが減少することで導入が効率化され、アプリケーションが期待される成果を達成すれば、不要な支出を削減できます。Hugging Faceからは、AIライブラリのリポジトリを通じて、企業は40万以上の事前にトレーニングされたLLM、15万以上のAIアプリケーション、10万以上のデータセットにアクセスできるため、AIを迅速かつ効率的に導入するための多くの選択肢があります。 形成者はLLMを独自のものにする企業 競争上の差別化やカスタマイズされたワークフローアプリケーションを必要とする企業にとって、既製のLLMやアプリケーションでは十分でない場合があります。形成者は、事前にトレーニングされたLLMを使用し、そのモデルを自社独自のデータセットを使用して微調整することで「形成」します。その結果、どんなプロンプトにも非常に具体的で正確な回答を提供するLLMが完成します。このモデルから恩恵を受けるアプリケーションには、以下が含まれますが、これらだけに限りません。 特定の業務機能に合わせてLLMを調整し、業務を効率化し、単調さを軽減するワークフローの自動化 内部ポリシー文書、規制ルール、または法的改正を比較して、特別な考慮が必要な違いを特定するためのAIサポート 特定のオペレーティングシステム、CLI、および文書に基づいてトレーニングされたCopilotによる、コード開発や文書検索の簡素化 RAG推論を活用 このシリーズの最初のブログで説明したように、推論システムはトレーニングされたAIアプリケーションをエンドユーザーやデバイスに提供します。モデルのサイズによって、推論は単一のGPUやサーバーに導入することも、複数のサーバーにアプリケーションを分散させてスケールとパフォーマンスを向上させるマルチノード導入として実施することもできます。 比較的新しい技術である「リトリーバルオーグメンテッドジェネレーション(RAG)」は、企業がAIモデルの開発や導入をカスタマイズするための興味深い手法を提供します。RAGは、外部のデータソースから取得した補足データを用いて、事前にトレーニングされたLLMを強化します。RAGを使用すると、ユーザーのクエリからベクトル埋め込みが取得されます。そのベクトル埋め込みに最も近い一致が、外部データソースに対するデータのクエリに使用されます。取得された最も関連性の高いテキストやデータの断片は、元のプロンプトと共にLLMに渡され、推論が行われます。元のプロンプトに関連するローカルデータを提供することで、LLMはその追加データと自らの知識を組み合わせて回答を生成できます。LLMを再度トレーニングすることなく、RAGは顧客やデバイスからのクエリに対して具体的かつ正確な回答を提供します。 RAGは、使用者モデルと形成者モデルの間に位置し、企業が市販のLLMを微調整せずに活用できる手段を提供します。しかし、元のプロンプトクエリと共に追加のデータソース(多くの場合、ベクトルデータベース)にアクセスする必要があるため、フロントエンド、外部データソース、LLM間のネットワーク接続には、高いパフォーマンスと非常に低いエンドツーエンドの遅延が求められます。 LLMの消費モデルが定義された後、企業はトレーニングと推論モデルのための導入モデルを選択する必要があります。次のブログでは、「構築」と「購入」の選択についてと、それぞれに関連するコストについて検討します。
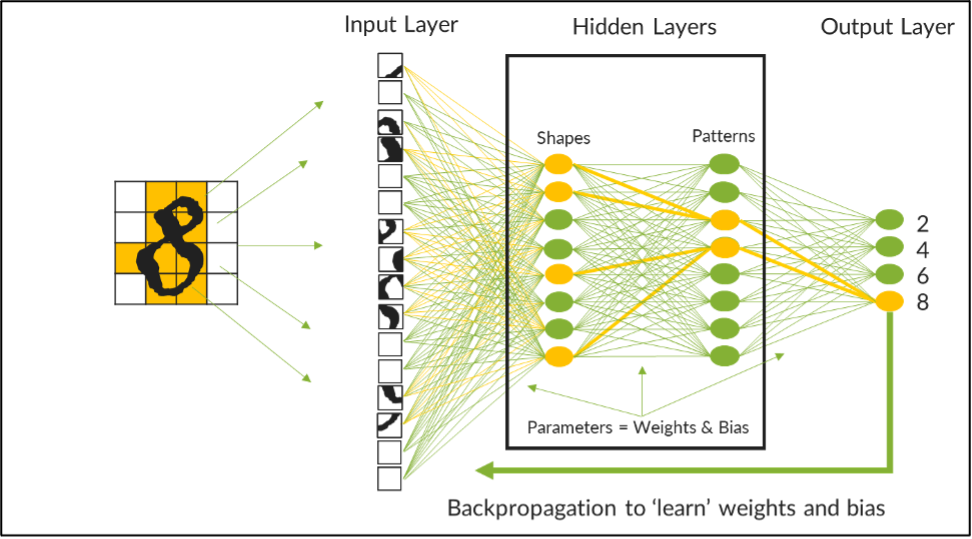
AIモデルのトレーニングは特別な課題です。Llama 3.1やGPT 4.0など、基盤となる大規模言語モデル(LLM)の開発には、世界中でもごくわずかな大企業だけが実現できるような莫大な予算とリソースが必要です。これらのLLMは、数十億から数兆個のパラメーターを持ち、合理的なジョブ完了時間内でトレーニングを行うためには、複雑なデータセンターファブリックの調整が必要です。例えば、GPT 4.0は1.76兆個のパラメーターを使用しています。 これらの数字を具体的にイメージするため、各パラメーターを1枚のトランプのカードに置き換えて考えてみましょう。52枚のトランプのデッキは約0.75インチ(約1.9cm)の厚さです。100万枚のカードを積み重ねるとエンパイアステートビルディングよりも高くなり、10億枚のカードを積み重ねると228マイル(約367キロメートル)の高さで地球の熱圏までに達し、1兆枚のカードを積み重ねると約227,000マイル(約365,000キロメートル)で、月までの距離に相当します。 AI投資を最大限に活用 多くの企業にとって、AIへの投資は新しいアプローチが必要です。それは、これらの基盤となるLLMを自社のデータで改良し、特定のビジネス上の課題を解決、そしてより深い顧客との関わりを提供することです。しかし、AIの導入が広がる中で、企業はデータプライバシーの強化やサービスの差別化を目的とした新たなAI投資の最適化方法を求めています。 ほとんどの企業にとって、これはオンプレミスのAIワークロードの一部を、プライベートデータセンターに移行することを意味します。「パブリッククラウド対プライベートクラウド」のデータセンター論争は、AIデータセンターにも当てはまります。多くの企業は、AIインフラを構築するという新しい課題に圧倒されています。確かに課題ではありますが、乗り越えられないものではありません。既存のデータセンターの知識を使用できます。少しのサポートがあれば大丈夫です。ジュニパーがそのガイド役を務めます。 このブログシリーズでは、AIへの投資を検討する企業にとってのさまざまな考慮事項と、ジュニパーが提唱するAIデータセンターのABCに基づくさまざまなアプローチについて紹介します。ABCとはつまり、アプリケーション(Application)、構築(Build)または購入(Buy)、コスト(Cost)を意味します。 まず初めに、なぜAIインフラがこれほどまでに特化される必要があるのかを見ていきましょう。 LLMおよびニューラルネットワークの理解 インフラの選択肢をよりよく理解するためには、AIアーキテクチャの基本と、AIの開発、提供、トレーニング、推論における基本的なカテゴリについて理解すると役立ちます。 推論サーバーは、インターネットに接続されたフロントエンドのデータセンターでホストされており、ユーザーやデバイスが完全にトレーニングされたAIアプリケーション(Llama 3など)にクエリを送信できるようになっています。TCPを使用すると、推論クエリやトラフィックのパターンは他のクラウドホスト型ワークロードと同様になります。リアルタイムで行われる推論では、一般的な中央処理装置(CPU)や、トレーニング時に使用されるのと同じグラフィック処理装置 (GPU)を用いることで、最速の応答と最低の遅延を提供します。これは通常、初回トークンの応答時間や、インクリメンタルトークンの時間といった指標で測定されます。要するに、これはLLMがクエリにどれだけ速く応答できるかを示しており、大きなスケールでは、一貫したパフォーマンスを維持するために大規模な投資と専門知識が必要になる場合があります。 一方で、トレーニングには特有の処理上の課題があり、特別なデータセンターのアーキテクチャが必要となります。トレーニングは、LLMやトレーニングデータセットが「無秩序な」インターネットから隔離された、バックエンドのデータセンターで行われます。これらのデータセンターは、400Gbpsや800Gbpsのネットワーキング接続を使用する、専用のレール最適化ファブリックを備えた高容量で高性能のGPUコンピューティングおよびストレージプラットフォームを使用して設計されています。大規模な「エレファント」フロー(大量データ転送)や広範囲なGPU間通信が発生するため、これらのネットワークは、数か月に及ぶ継続的なトレーニングサイクルに対応できるよう、容量、トラフィックパターン、トラフィック管理のニーズに合わせて最適化される必要があります。 トレーニングの完了までにかかる時間は、LLMの複雑さ、LLMをトレーニングするニューラルネットワーク内の層、精度向上のために調整すべきパラメーター、そしてデータセンターのインフラストラクチャの設計によって異なります。しかしニューラルネットワークとは何でしょう? そしてLLMの結果を改善するパラメーターとは何でしょう? ニューラルネットワークの基本 ニューラルネットワークとは、人間の脳の計算モデルを模倣するように設計されたコンピューティングアーキテクチャです。ニューラルネットワークは、データを取り込む入力層、結果を出力する出力層、そして入力された生データを有用な情報に変換する中間の隠れた層から成る、段階的な機能層で実装されています。ある層の出力が次の層の入力となり、クエリが体系的に分解、分析、処理されることで、各層のニューラルノード(または数学的関数)を通じて結果が生成されます。 例えば、下の画像は、最初の4つの偶数を示す手書きの数字を認識するために、LLMがニューラルネットワーク上で訓練される様子を示しています。このニューラルネットワークには2つの隠れた層があり、1つは形状を処理し、もう1つはパターンを認識します。手書きの数字のデータセットは小さなブロックに分割され、モデルに入力されます。最初の層では曲線や線が処理され、その後データは2番目の層に送られて、分析されている数字を示す可能性のあるデータ内のパターンが識別されます。 最適なLLM精度のためのパラメーター調整 各層内のニューラルノードは、ニューラルネットワーク接続のメッシュを持っており、これによりAI科学者は各接続に重みを適用できます。各重みは数値であり、特定の接続への関連性の強さを示します。例えば、データの上部四分割の1つにある曲線は「2」や「8」に対して重みが高い一方で、同じ四分割にある直線は「2」や「8」に対して重みが低いことになります。パターンを見る際に、縦の直線だけの組み合わせは「4」に対してつながりが強く重みは高いですが、直線と曲線が組み合わさると、「2」や「6」、「8」に対してよりつながりが強く重みは高くなります。 トレーニングの開始時には、モデルの結果は非常に不正確です。しかし、トレーニングを重ねることで、これらのニューラルのつながりの重みが調整または「チューニング」され、精度を段階的に向上させることができます。強いつながりと弱いつながりをさらに区別するために、各つながりには数値的なバイアスが適用され、強いつながりを強調し、弱いつながりを調整します。重みとバイアスはともに、LLMの精度を向上させるために調整する必要があるパラメーターを表します。 この簡単な例では、モデルが各数字を高い精度で識別できるようになるまでに、242個のパラメーターを繰り返し調整する必要があります。数十億または数兆個のパラメーターを扱う場合、このプロセスを自動化するため、逆伝播アルゴリズムが使用されます。それでもトレーニングは非常に長いプロセスであり、データセンターの基盤となる物理ネットワークで発生する処理によって遅延したり中断されることがあります。「テールレイテンシ」と呼ばれるこの遅延は、データセンターネットワークが適切に設計されていないと、トレーニングプロセスの時間とコストを大幅に増加させる可能性があります。 次のブログでは、企業がこれらの基盤となるLLMを活用して、自社のカスタムAIアプリケーションを導入し、プライベートデータセンターから提供する方法について説明します。 他の企業がこれらの課題に取り組むために、どのようにインフラストラクチャを構築しているか、ご興味はありますか? ぜひジュニパーのバーチャルイベント、「Seize the AI