





















Do you know what tools you have before you open your toolbox? Does what you find influence your direction or approach? “A good craftsman never blames his tools” may be interpreted in a few ways, but essentially it means one should ensure the satisfactory completion of work even when faced with challenges or deficits along the way. Selecting the right tool for the job is important, but first you must get a handle on what it is you are actually trying to achieve or solve. In a virtual world, your toolbox can be vast, tools can be easily modified and you get multiple attempts, but it all comes at a cost.
Experimentation can become computationally expensive and time is still a finite resource. Before selecting your tools or linking procedures, preparation is always key, as is understanding your problem domain and ultimate goal. And so a data scientist is tasked with understanding the wider problem space and delivering meaningful value, especially when helping to build services or products to tackle real world problems.
Data science itself is a discipline, one that seeks to unify statistics, data analysis, machine learning and related methods. It is crucial to the successful evolution and application of AI. While heavily mathematical, data science has its own specializations including researching new methods of analysis and creating new Machine Learning (ML) algorithms.
Tooling for Solutions
Rather than diving into tool selection, a data scientist must first become intimate with the problem at hand. They need to understand the domain in question and figure out not just what data is available and relevant, but how results can be used to facilitate outcomes. By also appreciating the context in which data is gathered, it leads to decisions about what features can be considered and how to standardize them as primitives which can be used in downstream models or across workflows.
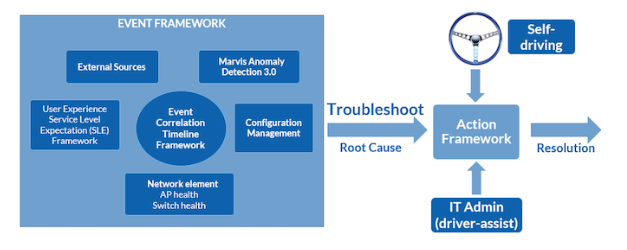
Figure 1.0 Example high-level problem space for network assurance
Figure 1.0 above shows one view of the challenges faced when using multiple sources and elements to build an AI-driven framework. Its goal is to solve network-related service delivery problems with modes that may involve human interaction or be fully autonomous.
When attempting to solve such a real-world problem with AI, rarely will one tool or a singular process address a network operator’s needs outright, so chaining of multiple intelligent services into pipelines or workflows is required. Tool selection is based upon an understanding of the problem space including knowing what resources are available and their constraints. Tools are a force multiplier but knowing where and how to apply the right “force” is based upon the experience and skill of the data scientist.
Most data scientists will tell you that a large majority of their time is initially spent preparing, cleaning or transforming data rather than the more interesting work of feature engineering and selecting (or training) ML models. Additionally, automating the ingestion of data in a robust and repeatable format poses its own set of challenges to solve. In the network space, many protocols and their PDUs (Protocol Data Units) such as IE (Information Elements) are standardized and well understood. You might think this gives us a good head start but it does not simplify the overarching complexity of trying to discern context, identify root causes or have an AI-driven platform suggest the right corrective actions for your particular organization.
As an example, to try and identify an AP (Access Point) in an abnormal state, we may have access to the AP’s control and data plane telemetry. We may also have historical data from customer APs that were found to be in an unhealthy state. This helps facilitate the labeling, training and testing of our models and although useful, the real question is which AP metrics and statistics comprise the key features and indicators we need. This is a supervised learning problem, one that also requires a dimension reduction as many of the variables have no bearing on the outcome. For efficiency we also need to know the minimal number of parameters or combinations thereof to give us the most efficient and confident classification. Feature engineering like this uses methods such as principal component analysis (PCA) or singular value decomposition (SVD) for appropriate models to be generated. Subsequently, different ML methods may also be tested to see which provide the best fit. Using ensemble learning (testing multiple models for the best performing one) can also help arrive at better and more accurate outcomes (ones that yield greater accuracy and thus confidence). These processes are opaque to us as users of a platform but represent only one of many steps in the productization of AI-platforms.
To create a scalable, autonomous and constantly learning platform that’s also user-friendly while solving real-world challenges is a complex undertaking. Another challenging component of the framework above is that of anomaly detection using unsupervised learning to move from identifying statistical anomalies to business anomalies. In the next blog, we will take a closer look at anomaly detection in detail.
Additional blogs in this series
Decision-making with Real AI Beats a 6th Sense Every Time
Assistants, Chatbots and AI-Driven Frameworks
Anomaly Detection in Networks and a Few Tools in the Box


