





















Data is the plural of datum, a single piece of information. Raw data is unrefined like ore and has less value than when it is processed, organized and structured. Once operated upon and contextualized, data becomes more valuable information but still may be in a somewhat fundamental form. Great AI (artificial intelligence) starts with great data, and when processing it for use in machine learning (ML), we convert it to intermediate primitive forms. These primitives may represent a single item, an aggregate or could be a derivative with meaning such as a metric. These primitives can be optimized for and once consumed, can be reused or referenced by additional models.
For the efficient use of resources, creating, gathering and selecting the right data is key. To solve a real-world problem, early questions asked are often “what do we know and how”, “what do we not know”, and “how do we find out more”. Checking what data is currently available (including its validity and applicability) leads to further questions about whether more and better data is required, sourced from where and used for what.
Figure 1.0 Data and primitives as fuel for AI.
Data Sources
Where does the data come from? Dependent upon the problem space, data may be sourced from multiple locations, but it has to be made available and then collected in some way. Point in time data may be useful for certain tasks, but in dynamic problem spaces, regular and fresh data is required constantly. For our purposes we will focus on network operations and related service assurance data where the data is a representation of an object, item or state. The majority of this data may be telemetry via instrumentation, though some discrete data such as configurations or thresholds are sometimes needed to provide context. Networks and their end users are rarely static entities, so by using continuously streamed measurement and event data we can provide a more granular and temporal context (especially when compared to traditional polling methods).
Greater fidelity of data gives us more granular capabilities, but to be used for what? Instrumenting a service end-to-end is challenging and especially so when trying to facilitate autonomous troubleshooting performed by an AI-driven framework . With the right data, models and optimizations, we can see deeper into the fabric of our networks to increase observability and take full advantage of the opportunities that come with it.
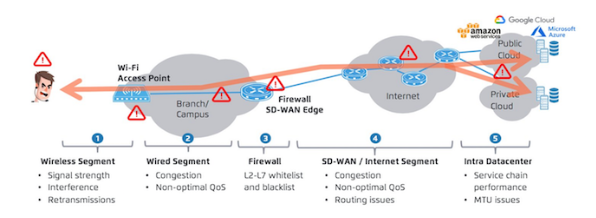
Networks exist to facilitate flows, but as this energy is transported end-to-end, multiple network conditions can affect the quality and user experience. We require flows to be integral, reliable and resilient, yet the overall user experience has dependencies on device configurations and the availability of critical upstream or downstream service dependencies. Some transport mediums do not guarantee reliable delivery so additional instrumentation is required to identify when there are issues, but what really matters most is identifying and fixing any resultant user experience issues before they become fully fledged problems.
Modern network elements expose many metrics, but not all are capable of providing streaming data related to individual user flows. Many legacy devices focus primarily on the health of their own control planes and high-level interface statistics. While this macro data is useful from one perspective, it is rarely streamed which leads to a need for inbound and resource-intensive polling by network management stations. But what if network elements had a better concept of the metrics that mattered to an individual user’s experience? What if they could stream that data with the granularity required for an AI platform to constantly ingest and learn about specific micro-conditions rather than just the macro-level ones? This is the challenge for modern network operators where network elements themselves must become more service-aware and even localize the context all the way down to an individual device and user’s experience.
Bottom-Up Debugging
Raw data is often high volume, noisy and can be a mix of data sources, but once consolidated and transformed to the right level of abstraction, our AI data primitives can become vendor-independent across a range of common services. This abstraction layer is pivotal for enabling the ingestion of data from different but similar classes of devices.
Mist Access Points (APs) for example, were built from the ground up with a new architecture that emits not just standard network element statistics, but high-volume detailed data related to individual users and their application-level experiences. These APs send thousands of metrics each minute and embrace a more user-centric than device-centric approach. By wrapping additional telemetry around individual users and their quality of experience a new level of fidelity is reached. This newly found richness and depth is one that AI and machine learning can mine, model and translate into actionable insights applied per-user or across the whole network.
By fundamentally rethinking the data model (including what’s generated, queryable and emitted) while using a more service-centric and user-centric approach, greater possibilities present themselves to inspect and correlate across complex dependencies. Once this higher cardinality data is created and consumed, greater observability is facilitated. This data can also be recombined, analyzed and mined by AI in new and novel ways for analytics or new services.
This path also empowers increased overall controllability and precision for everything from targeted messaging to specific optimizations and even to accelerate the evolution of the platforms themselves. In a world where SLEs (Service Level Expectations) have been heightened, increased confidence is required to both set and meet service levels. If, for example, the primitives optimized for are SLE-related, such as a user’s WLAN association and authentication events or their DNS response times, we can then teach an AI and its chatbot to understand what metrics and actions contribute to successful or unsuccessful outcomes.
Network fabrics are complex distributed systems that traditionally used simple monitoring and metrics but when their observability is increased, a greater amount of internal and edge states can be represented. The ability to determine not just the behavior of the system as a whole, but that of its constituent parts is elevated. More questions can be asked and answered. This also allows for one of the goals of an AI-driven framework which is to continuously learn and improve while enhancing our human capabilities. Whether it is structured or unstructured data, or a mix of supervised and unsupervised learning, the right primitives mean learning modes and workflows can be chained together for greater context and to deliver better business value.
When the data, baselines and networks keep changing, how can you keep pace with accelerating complexity other than by enhancing your team’s capabilities? From the ore of raw data to the precious gems of corrective actions, an AI-powered chatbot can unearth solutions while easing burdens to ensure you stay in control.
Additional blogs in this series
Decision-making with Real AI Beats a 6th Sense Every Time
Assistants, Chatbots and AI-Driven Frameworks
Anomaly Detection in Networks and a Few Tools in the Box


