





















Il est particulièrement difficile d’entraîner des modèles d’IA. Développer de grands modèles de langage (LLM) de fondation (comme Llama 3.1 et GPT 4.0) nécessite des ressources et des budgets colossaux, ce que seules les plus grandes entreprises du monde peuvent se permettre. Ces LLM regroupent des milliards, voire des milliers de milliards, de paramètres, et la fabric du datacenter doit pouvoir s’adapter pour les entraîner dans un délai raisonnable. GPT 4.0, par exemple, utilise pas moins de 1 760 milliards de paramètres !
Pour mettre ces chiffres en perspective, imaginez que chaque paramètre représente une carte à jouer. Un paquet de 52 cartes mesure environ 2 cm d’épaisseur. Une pile d’un million de cartes serait plus haute que l’Empire State Building, une pile d’un milliard de cartes mesurerait 366 km de haut (soit l’altitude de la thermosphère) et une pile de mille milliards de cartes s’étendrait sur plus de 365 000 km, soit approximativement la distance entre la Terre et la lune.
Rentabiliser au mieux les investissements dans l’IA
Pour bon nombre d’entreprises, investir dans l’IA impose d’adopter une nouvelle approche : affiner ces LLM de fondation avec leurs propres données pour résoudre des problèmes métiers spécifiques ou renforcer l’engagement client. Mais alors que l’adoption de l’IA gagne du terrain, les entreprises recherchent de nouveaux moyens d’optimiser leurs investissements dans l’IA afin de renforcer la protection des données tout en offrant des services différenciés.
Pour la plupart d’entre elles, cela suppose de migrer une partie de leurs charges de travail IA sur site vers des datacenters privés. L’éternel débat entre cloud public et cloud privé concerne également les datacenters IA. Nombreuses sont les entreprises qui se sentent intimidées par l’idée de créer une infrastructure d’IA. Pourtant, si le parcours est jalonné d’obstacles, ceux-ci n’ont rien d’insurmontable. Vous pouvez tirer parti de toutes vos connaissances actuelles en matière de datacenter. Vous aurez simplement besoin d’un petit coup de pouce, et Juniper est là pour vous aider.
Dans cette série d’articles, nous allons examiner les différents facteurs que doivent prendre en compte les entreprises qui cherchent à investir dans l’IA et expliquer comment les différentes approches s’articulent autour de ce que Juniper appelle Les fondamentaux des datacenters IA : les applications, les coûts et le dilemme entre développer et acheter.
Mais tâchons d’abord de comprendre pourquoi l’infrastructure d’IA nécessite un tel niveau de spécialisation.
Comprendre les LLM et les réseaux de neurones
Pour mieux comprendre les différentes options d’infrastructure, il peut être judicieux de connaître quelques concepts fondamentaux des architectures d’IA et d’assimiler les principales catégories de développement, de prestation, d’entraînement et d’inférence dans le domaine de l’IA.
Les serveurs d’inférence sont hébergés dans des datacenters front-end connectés à Internet, d’où les utilisateurs et les appareils peuvent interroger une application d’IA entièrement entraînée (Llama 3 par exemple). Avec le protocole TCP, les requêtes d’inférence et les schémas de trafic reproduisent ceux des autres charges de travail hébergées dans le cloud. Fonctionnant en temps réel, les serveurs d’inférence peuvent utiliser des processeurs (CPU) courants ou des processeurs graphiques (GPU) similaires à ceux utilisés pour l’entraînement afin d’offrir les meilleurs temps de réponse avec un minimum de latence, des performances généralement mesurées à l’aide d’indicateurs tels que le TTFT (time-to-first-token) et le TTIT (time-to-incremental-token). En substance, ces indicateurs reflètent la rapidité avec laquelle le LLM est capable de répondre à des requêtes ; à grande échelle, garantir des performances homogènes peut demander de lourds investissements et des connaissances de pointe.
L’entraînement, quant à lui, implique certaines problématiques de traitement bien particulières qui supposent de recourir à des architectures de datacenter spécialisées. La partie entraînement intervient dans des datacenters backend, où les LLM et les datasets d’entraînement sont isolés d’Internet. Ces datacenters intègrent une puissance de calcul GPU et des plateformes de stockage haute capacité et hautes performances, combinées à des fabrics « rail-optimized » spécialisées utilisant des interconnexions réseau 400 Gbit/s et 800 Gbit/s. Devant gérer de vastes « flux éléphants » et une communication intensive entre les processeurs graphiques, ces réseaux doivent être optimisés en fonction des demandes de capacité, des schémas de trafic et de la gestion du trafic de cycles d’entraînement continus pouvant durer des mois.
La durée d’exécution d’un entraînement dépend de la complexité du LLM, des couches utilisées dans le réseau de neurones pour l’entraîner, du nombre de paramètres à ajuster pour améliorer la précision et de la conception de l’infrastructure de datacenter. Mais qu’est-ce qu’un réseau de neurones et quels sont les paramètres utilisés pour affiner les résultats d’un LLM ?
Réseaux de neurones : les bases
Un réseau de neurones est une architecture informatique conçue pour simuler le modèle computationnel du cerveau humain. Ces réseaux sont implémentés dans un ensemble de couches fonctionnelles progressives comprenant une couche d’entrée dédiée à l’ingestion de données, une couche de sortie réservée à la présentation des résultats, ainsi que des couches intermédiaires cachées, qui traitent les données d’entrée brutes pour les convertir en informations exploitables. La sortie d’une couche sert d’entrée à une autre couche. De cette manière, sur chaque couche, il est possible de décomposer, d’analyser et de traiter les requêtes de manière systématique sur plusieurs ensembles de nœuds neuronaux (ou de fonctions mathématiques) jusqu’à l’obtention de résultats.
Par exemple, l’image ci-dessous représente un LLM entraîné sur un réseau de neurones afin de reconnaître les chiffres manuscrits des quatre premiers nombres pairs. Ce réseau de neurones possède deux couches cachées : une pour traiter les formes, l’autre pour reconnaître des schémas. Après avoir été décomposés en blocs de petite taille, les datasets de nombres manuscrits alimentent le modèle. Les courbes et les lignes sont fonctionnellement traitées au niveau de la première couche avant d’être envoyées à la seconde couche afin d’identifier parmi les données les schémas susceptibles d’indiquer le nombre analysé.
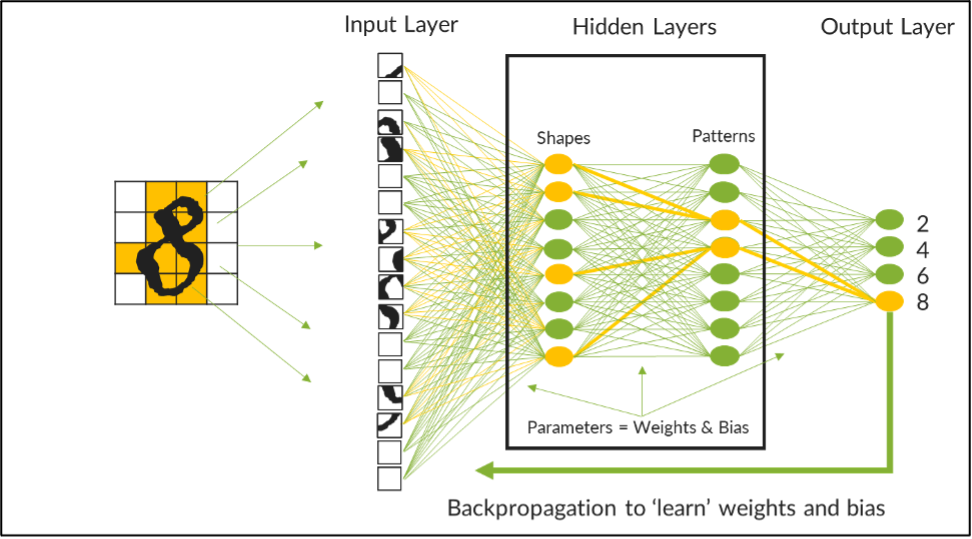 Ajuster les paramètres pour maximiser la précision des LLM
Ajuster les paramètres pour maximiser la précision des LLM
Entre chaque couche, des connexions pondérées (selon les instructions d’ingénieurs IA) relient les nœuds neuronaux. Chaque pondération est une valeur numérique qui indique la force de l’association à une connexion donnée. Par exemple, dans le quadrant supérieur de l’image, une courbe est plus fortement associée à un 2 ou un 8, tandis qu’une ligne a une pondération plus faible pour ces chiffres. Si l’on observe l’ensemble de l’image, les lignes verticales et droites sont plus fortement associées à un 4, tandis qu’un mélange de courbes et de lignes est plus fortement associé à un 2, un 6 ou un 8.
Au début de l’entraînement, il est impossible d’obtenir du modèle des résultats précis. Cependant, au fil des entraînements, il devient possible d’ajuster ou « d’adapter » les pondérations de ces connexions neuronales afin d’en améliorer progressivement la précision. Pour mieux distinguer les connexions fortes des connexions faibles, un biais numérique est appliqué à chaque connexion afin d’amplifier les connexions fortes et de modérer les connexions négatives. Ensemble, les pondérations et les biais constituent les paramètres à adapter pour affiner la précision d’un LLM.
Ce modeste exemple compte 242 paramètres qui doivent être adaptés et réadaptés jusqu’à ce que le modèle puisse identifier chaque nombre avec un degré de précision élevé. Lorsque les modèles comptent des milliards, voire des milliers de milliards, de paramètres, des algorithmes de rétropropagation sont utilisés pour automatiser le processus. Quoi qu’il en soit, l’entraînement est un processus extrêmement long, qui peut être retardé ou interrompu par des latences de traitement susceptibles de se produire dans le réseau physique sous-jacent du datacenter. À moins de concevoir correctement le réseau de datacenter, cette « latence de queue » peut considérablement allonger les délais de traitement et alourdir le coût du processus d’entraînement.
Dans notre prochain article de blog, nous vous expliquerons comment les entreprises peuvent exploiter ces LLM fondamentaux pour déployer leurs propres applications d’IA personnalisées à partir de datacenters privés.
Curieux de savoir comment les autres organisations conçoivent leur infrastructure pour surmonter ces obstacles ? Retrouvez-nous à notre événement virtuel Seize the AI Moment pour connaître les points de vue de grands noms tels qu’AMD, Intel, Meta, PayPal et bien d’autres.


