





















En janvier 2024, Juniper a lancé l’AI-Native Networking Platform. Son but : exploiter les bonnes données via la bonne infrastructure et ainsi fournir les réponses adéquates pour assurer des expériences utilisateur et opérateur optimales. Qu’il s’agisse d’exploiter l’IA pour simplifier les opérations réseau ou d’optimiser les fabrics Ethernet pour l’IA afin d’améliorer les workloads d’IA et les performances GPU, Juniper tient les promesses de l’Experience-First Networking.
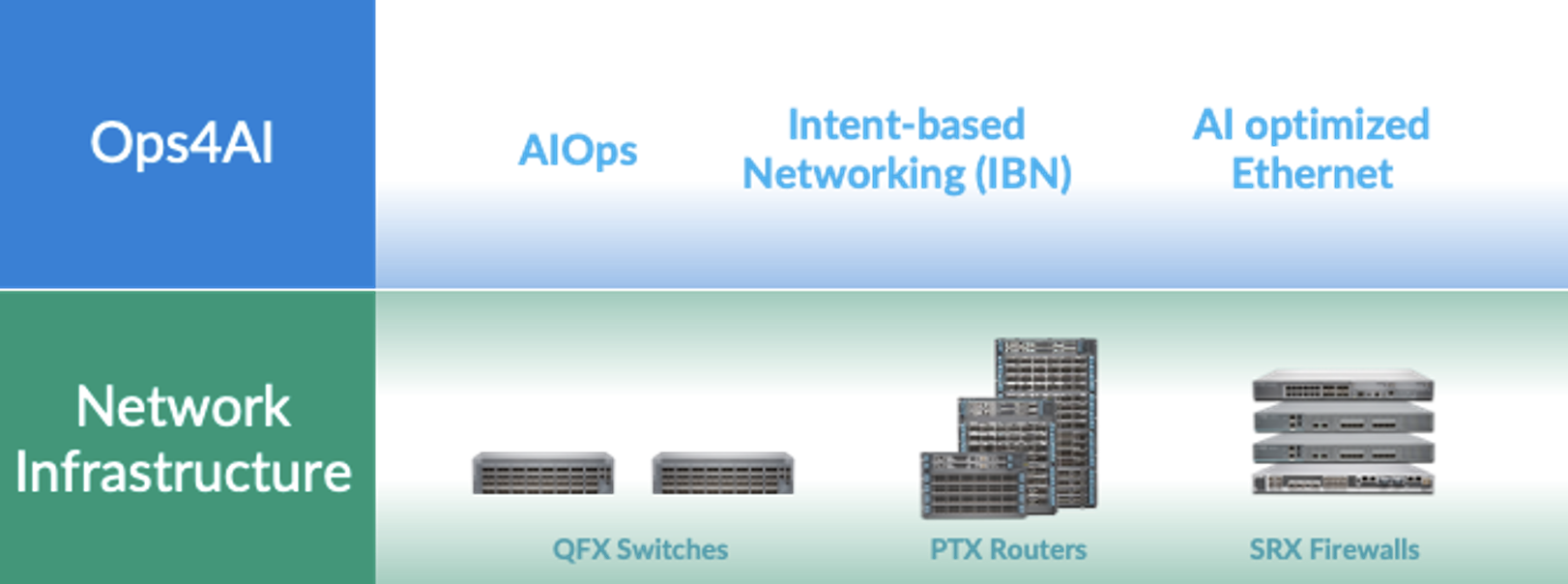
Fort de sa longue expérience de fournisseur d’infrastructures de réseaux de datacenters hautes performances, avec les commutateurs QFX, les routeurs PTX et les pare-feu SRX, Juniper est fier d’annoncer que son architecture de réseaux IA natifs s’étend encore et inclut désormais des opérations multifournisseurs de bout en bout pour les datacenters IA. Porteuse de grandes améliorations, notre nouvelle solution Ops4AI se montrera indispensable pour les clients. Ops4AI comprend une combinaison unique des composants Juniper Networks suivants :
- AIOps dans le datacenter basé sur l’assistant de réseau virtuel Marvis
- Automatisation basée sur l’intention via la gestion de fabrics de datacenters multifournisseurs avec Juniper Apstra
- Ethernet optimisé pour l’IA, avec RoCEv2 pour IPv4/v6, la gestion des congestions, l’équilibrage de charge et la télémétrie
Ops4AI accélère le délai de rentabilisation des datacenters IA hautes performances, réduit les coûts opérationnels et simplifie les processus. Et la solution est encore plus performante grâce à plusieurs nouveautés : Juniper Ops4AI Lab, notre nouveau laboratoire multifournisseur permettant aux clients de tester des modèles et des workloads d’IA, qu’ils soient privés ou open source ; des conceptions validées Juniper pour garantir la bonne configuration des réseaux dédiés à l’IA utilisant Juniper, Nvidia, Broadcom, Intel, Weka et d’autres partenaires ; des améliorations apportées à Junos et Apstra pour optimiser les réseaux des datacenters — ce dont nous allons justement parler.
Découvrons les améliorations apportées à Junos® et à Apstra sans plus attendre.
Ajustement automatique des fabrics pour l’IA
L’accès direct à la mémoire à distance (RDMA) des GPU génère un trafic massif sur les réseaux IA. Dans certaines circonstances (par exemple, lorsque plusieurs GPU envoient du trafic vers un seul GPU au niveau du dernier commutateur de saut), une congestion peut se produire malgré des techniques comme l’équilibrage de charge. Lorsque cela se produit, il faut compter sur des techniques de contrôle comme DCQCN (Data Center Quantified Congestion Notification), qui associe des fonctionnalités telles que la notification de congestion explicite (ECN) et le contrôle de priorité des flux (PFC) pour calculer et configurer les paramètres qui garantiront les meilleures performances pour chaque file d’attente, chaque port et chaque commutateur. Régler manuellement ces paramètres pour des milliers de files d’attente sur l’ensemble des commutateurs est compliqué et fastidieux.
C’est pourquoi Apstra collecte régulièrement des données télémétriques sur ces files d’attente et ports, et les utilise pour calculer les paramètres ECN et PFC optimaux pour chacun d’entre eux. À l’aide de l’automatisation en boucle fermée, ces paramètres sont configurés sur tous les commutateurs du réseau.
Cette solution applique les meilleurs paramètres de contrôle des congestions, ce qui simplifie considérablement les opérations et réduit la latence et les temps d’exécution des tâches. Pour épauler nos clients qui investissent déjà grandement dans l’infrastructure d’IA, nous avons décidé de proposer ces fonctionnalités dès maintenant dans Juniper Apstra, sans frais supplémentaires. Visionnez une démo du dernier Cloud Field Day pour les voir en action. Nous avons également ajouté cette application à GitHub.
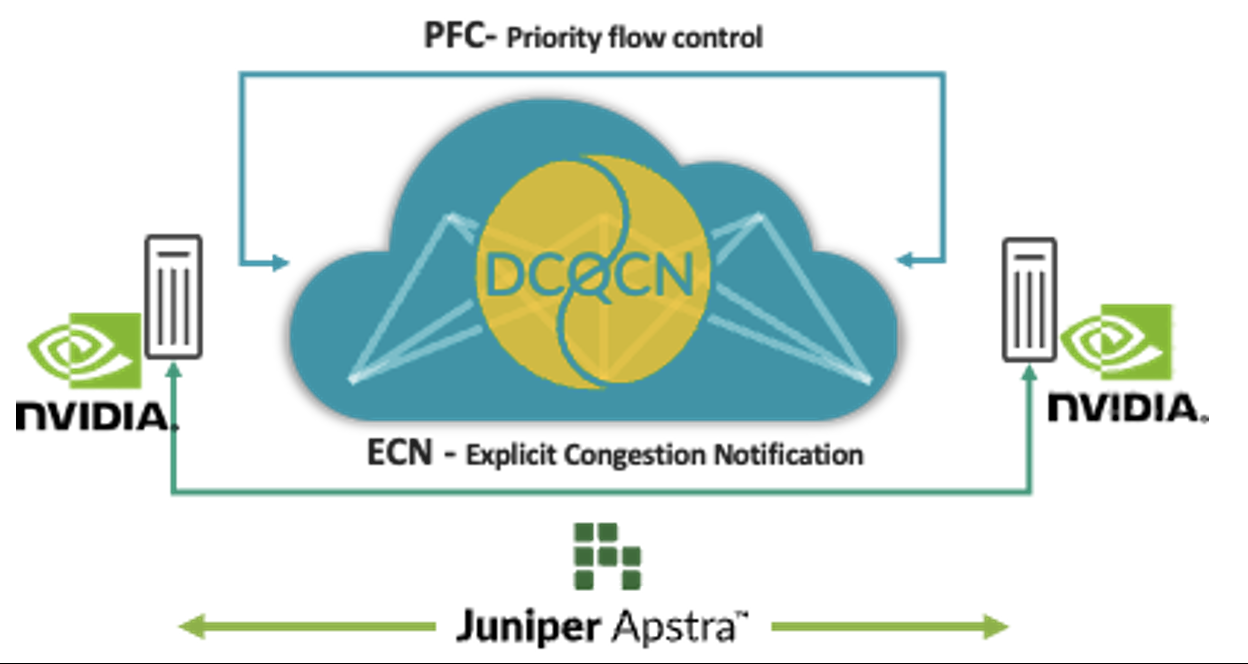 Figure 1 : Ajustement automatique des fabrics pour l’IA
Figure 1 : Ajustement automatique des fabrics pour l’IA
Équilibrage de charge global (GLB)
Le trafic des réseaux d’IA présente des caractéristiques uniques. Il est principalement alimenté par le trafic RDMA des GPU, qui consomme une bande passante élevée avec des flux moins nombreux, mais plus importants (souvent appelés « flux éléphants »). Par conséquent, l’équilibrage de charge statique basé sur le hachage à 5 uplets ne fonctionne pas bien. Plusieurs flux éléphants sont dirigés vers le même lien, ce qui entraîne une congestion et ralentit les temps d’exécution des tâches, une catastrophe pour les grands clusters GPU.
Pour résoudre ce problème, l’équilibrage de charge dynamique (DLB) prend en compte l’état de la liaison montante sur le commutateur local.
Par rapport à l’équilibrage de charge statique traditionnel, le DLB améliore considérablement l’utilisation de la bande passante de la fabric. Mais le DLB a ses limites. Notamment, il ne suit que la qualité des liens locaux au lieu de visualiser la qualité de l’ensemble du chemin entre le nœud d’entrée et le nœud de sortie. Supposons que nous ayons une topologie CLOS et que le serveur 1 et le serveur 2 essaient tous deux d’envoyer des données appelées respectivement flux-1 et flux-2. Avec le DLB, leaf-1 n’analyse que l’utilisation des liens locaux et prend des décisions en s’appuyant uniquement sur la table de qualité du commutateur local où les liens locaux peuvent être en parfait état. Par contraste, l’équilibrage de charge global (GLB) permet de visualiser la qualité globale du chemin, en repérant les problèmes de congestion au niveau spine-leaf.
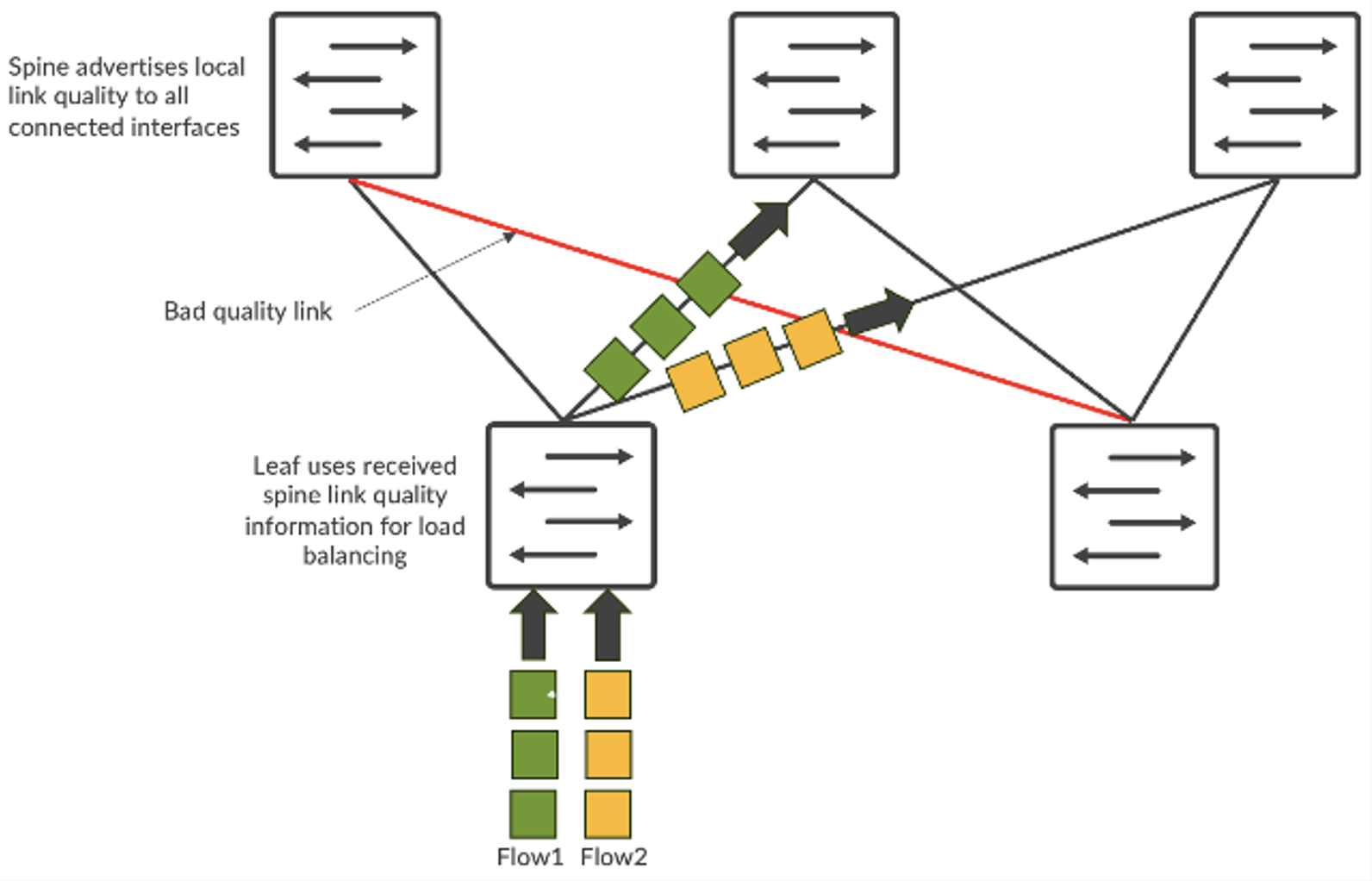 Figure 2 : Équilibrage des flux
Figure 2 : Équilibrage des flux
Il s’agit d’un système similaire à Google Maps, où l’itinéraire sélectionné est basé sur une vue d’ensemble.
Cette fonctionnalité choisit le chemin réseau optimal et permet de réduire la latence, d’améliorer l’utilisation du réseau et d’accélérer l’exécution des tâches. Résultats : les workloads d’IA enregistrent de meilleures performances et les précieux GPU sont davantage utilisés.
Visibilité de bout en bout, du réseau aux SmartNIC
Aujourd’hui, les administrateurs peuvent localiser les congestions en observant uniquement les commutateurs réseau. Mais ils n’ont aucune visibilité sur les points de terminaison précis (les GPU, dans le cas des datacenters IA) touchés par la congestion. Il est donc difficile d’identifier et de résoudre les baisses de performances. Lorsque plusieurs tâches d’entraînement sont lancées en parallèle, les données de télémétrie des commutateurs ne suffisent plus à déterminer quelles tâches ont été ralenties par la congestion : il faut vérifier manuellement (et péniblement) les statistiques RoCE v2 de la carte réseau de chaque serveur.
Pour résoudre le problème, Juniper Apstra tire désormais de riches flux de télémétrie RoCE v2 des SmartNIC des serveurs IA. Une fois corrélées avec la télémétrie existante des commutateurs, ces nouvelles données sont précieuses : elles accélèrent les workflows de visibilité et de débogage lorsque des problèmes de performances surviennent, elles améliorent la vue globale du réseau et permettent de mieux comprendre les dynamiques causées par le comportement du réseau et des serveurs IA. Les données en temps réel fournissent des informations sur les performances du réseau, les schémas de trafic, les points de congestion potentiels et les points de terminaison touchés, ce qui permet d’identifier les goulots d’étranglement et les anomalies.
Avec une meilleure observabilité du réseau et un débogage simplifié des problèmes de performances, il devient possible prendre des mesures en boucle fermée pour améliorer les performances globales du réseau. Par exemple, la surveillance des paquets désordonnés par les SmartNIC permet d’ajuster la fonctionnalité intelligente d’équilibrage de charge du commutateur. Avec l’infrastructure IA, qui dit visibilité de bout en bout dit performances optimales.
 Figure 3 : Visibilité de bout en bout, du réseau aux SmartNIC
Figure 3 : Visibilité de bout en bout, du réseau aux SmartNIC
Pour en savoir plus, ne manquez pas notre événement en ligne « Seize the AI Moment » le 23 juillet. Des clients importants de Juniper et des grands noms du secteur nous mettront au fait des dernières évolutions dans les infrastructures de datacenters IA.
Déclaration relative à l’orientation produit. Juniper Networks peut divulguer des informations prévisionnelles ou des informations sur le développement des futurs produits, fonctionnalités ou améliorations par le biais d‘une « déclaration relative à l’orientation produit » ou d‘un « plan prévisionnel ». Ces détails sont basés sur les efforts et les plans de développement actuels de Juniper. Ces efforts et plans de développement sont susceptibles d’être modifiés à la seule discrétion de Juniper, sans préavis. Sauf mention contraire incluse dans un accord définitif, Juniper Networks n’offre aucune garantie et n’accepte aucune responsabilité quant à la mise à disposition des produits, des fonctionnalités ou des améliorations décrits sur ce site Web, cette présentation, cette réunion ou cette publication. Juniper n’est pas non plus responsable de toute perte résultant de la confiance accordée au plan prévisionnel. Les décisions d’achat prises par des tiers ne doivent pas se fonder sur ce plan prévisionnel, et aucun achat ne peut dépendre de la mise à disposition par Juniper Networks d’une capacité ou d’une fonctionnalité décrite sur ce site Web, cette présentation, cette réunion ou cette publication.


