





















An AI cluster is only as good as the network behind it. It’s easy for a networking vendor to say that, but it’s true. At Juniper Networks, we believe that unlocking the power of AI means ensuring the network is never the bottleneck in AI model training performance and GPU job completion time.
CEO, Rami Rahim recently shared how the Juniper approach to networking AI data centers is based on a high-performance portfolio, a commitment to open standards, such as Ethernet, and an experience-first operations mindset. Let’s dig into the experience-first philosophy and see how Juniper makes it easy with Apstra, taking the pain out of plying AI models in the making.
Rails of the Road
Juniper is broadly working on AI cluster solutions for inference and training with many GPU vendors like Intel, AMD, NVIDIA and more. Presently, our customers are asking most about NVIDIA, not only because of its preeminent demand, but also because when deploying DGX servers and similar HGX-based servers from other vendors, NVIDIA prescribes its networking in a fashion that surprises most data center network architects and operators. It’s a different design, dubbed “rail optimization”.
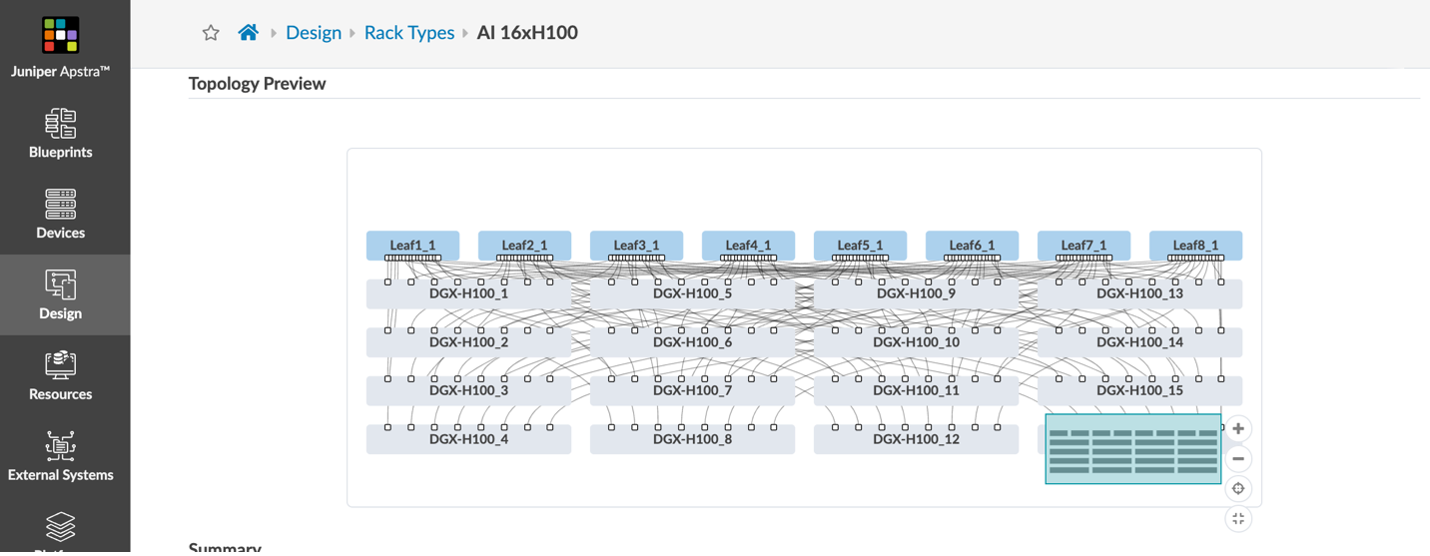
A rail-optimized design comes from the fact that the NVIDIA Collective Communications Library (NCCL) and its PXN feature discover the network topology and optimize communications latency. Crucially, that topology includes the NVIDIA NVLink switch in the server itself that connects eight A100 or H100 GPUs. Aside from the out-of-band management interface, frontend management interface and storage interface(s), each server has eight network interfaces; one per GPU. These are either 200GE or 400GE interfaces for the A100 and H100, respectively. Each GPU interface is cabled to a separate leaf switch. That’s right. Each server is connected to eight leaf switches, and that’s only the GPU compute fabric.
In such AI clusters with these servers, the frontend, storage and backend GPU compute interfaces are generally kept on separate, dedicated networks. Those familiar with Juniper Apstra will know that it can help manage all three fabrics as blueprints in the same Apstra instance.
We’ll focus on the GPU fabric because it’s a bit of a curveball to most networking professionals. Juniper uses Apstra’s flexible intent-based design components to publish logical devices for servers and many switching port profiles that are common in such AI clusters’ GPU fabrics. To do so, we’ve employed Terraform HCL and open sourced these configurations so they’re easily applied into any Apstra instance, thanks to the Terraform Provider for Apstra.
Making Rails Regular with Apstra
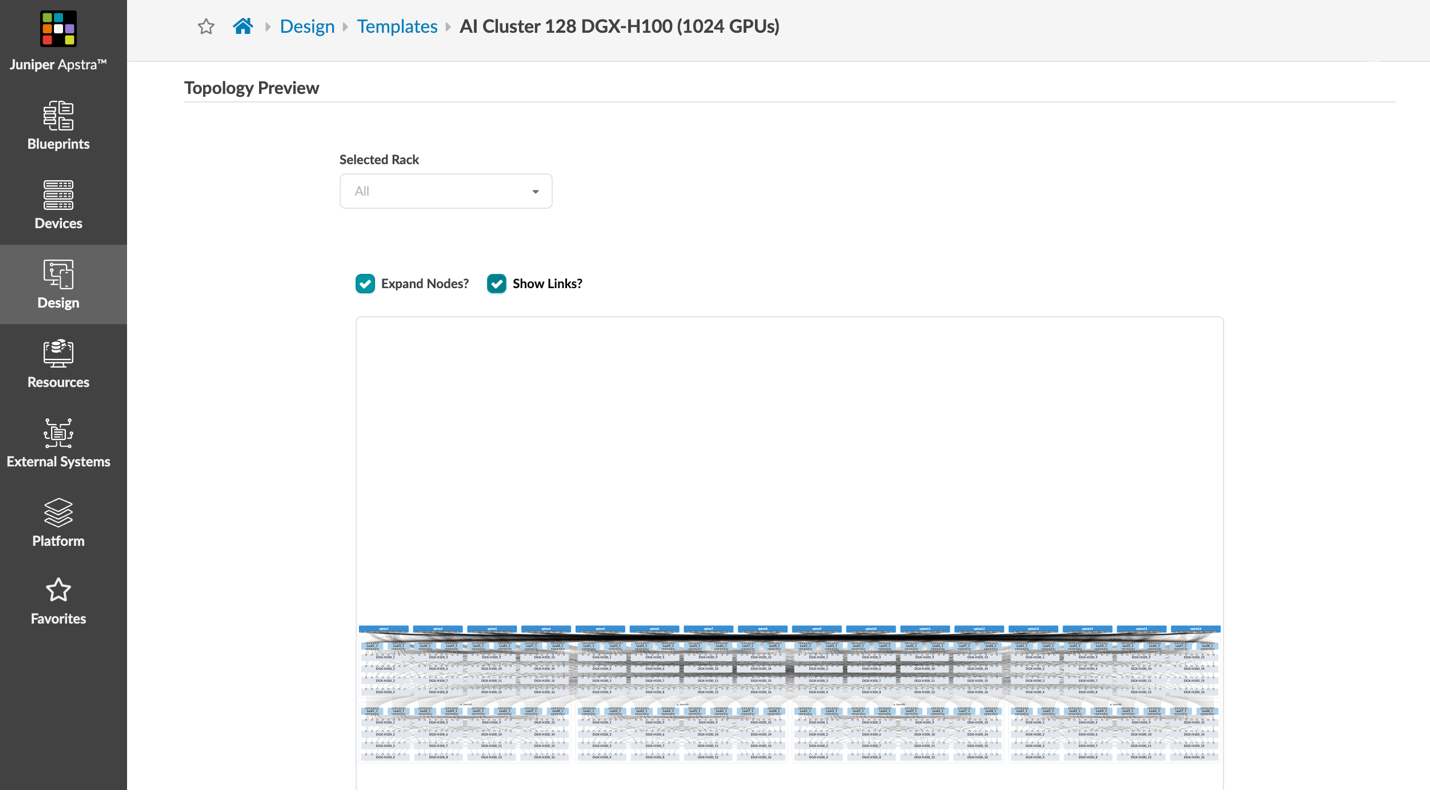
As shown in Figures 1 and 2 below, the A100-based server’s and H100-based server’s eight 200GE or 400GE interfaces are modelled after a simple “Terraform apply” command is pointed at Apstra. There are many other logical device profiles set up as starting points for AI clusters.
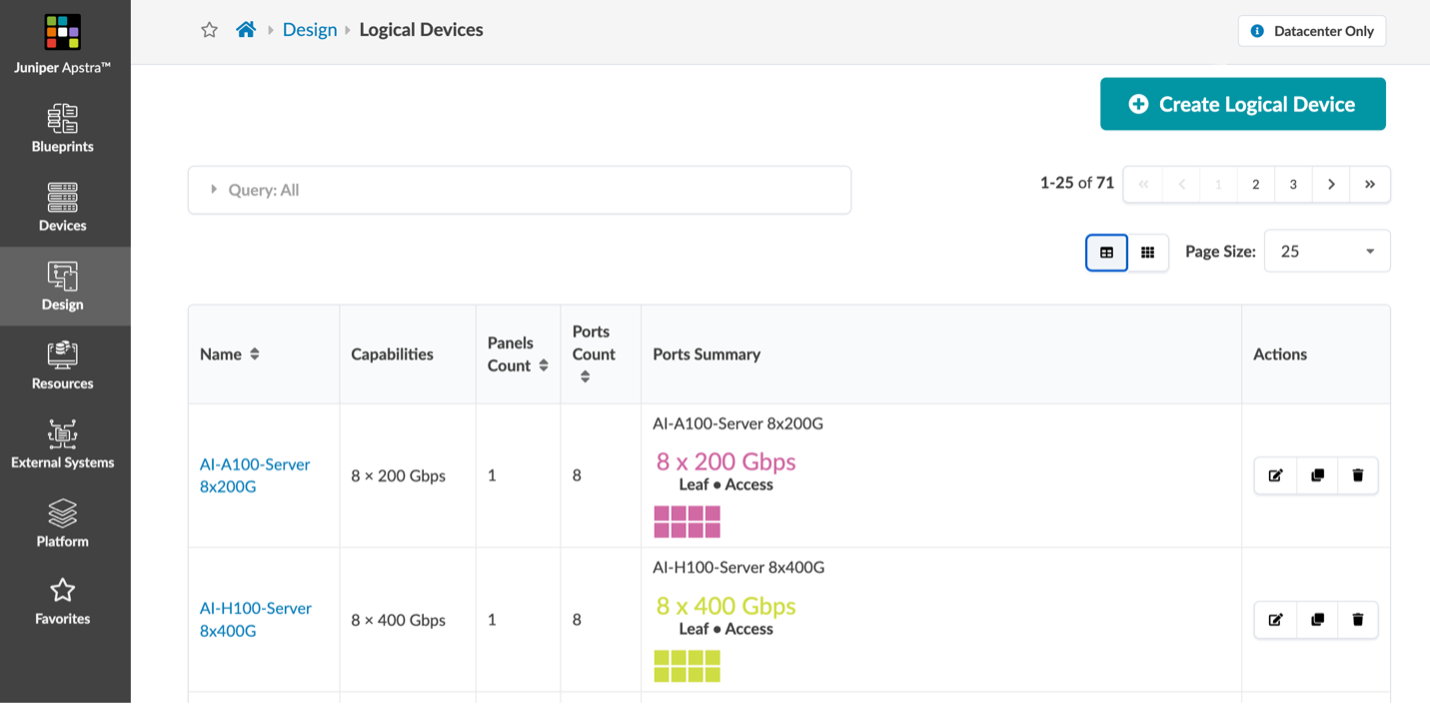
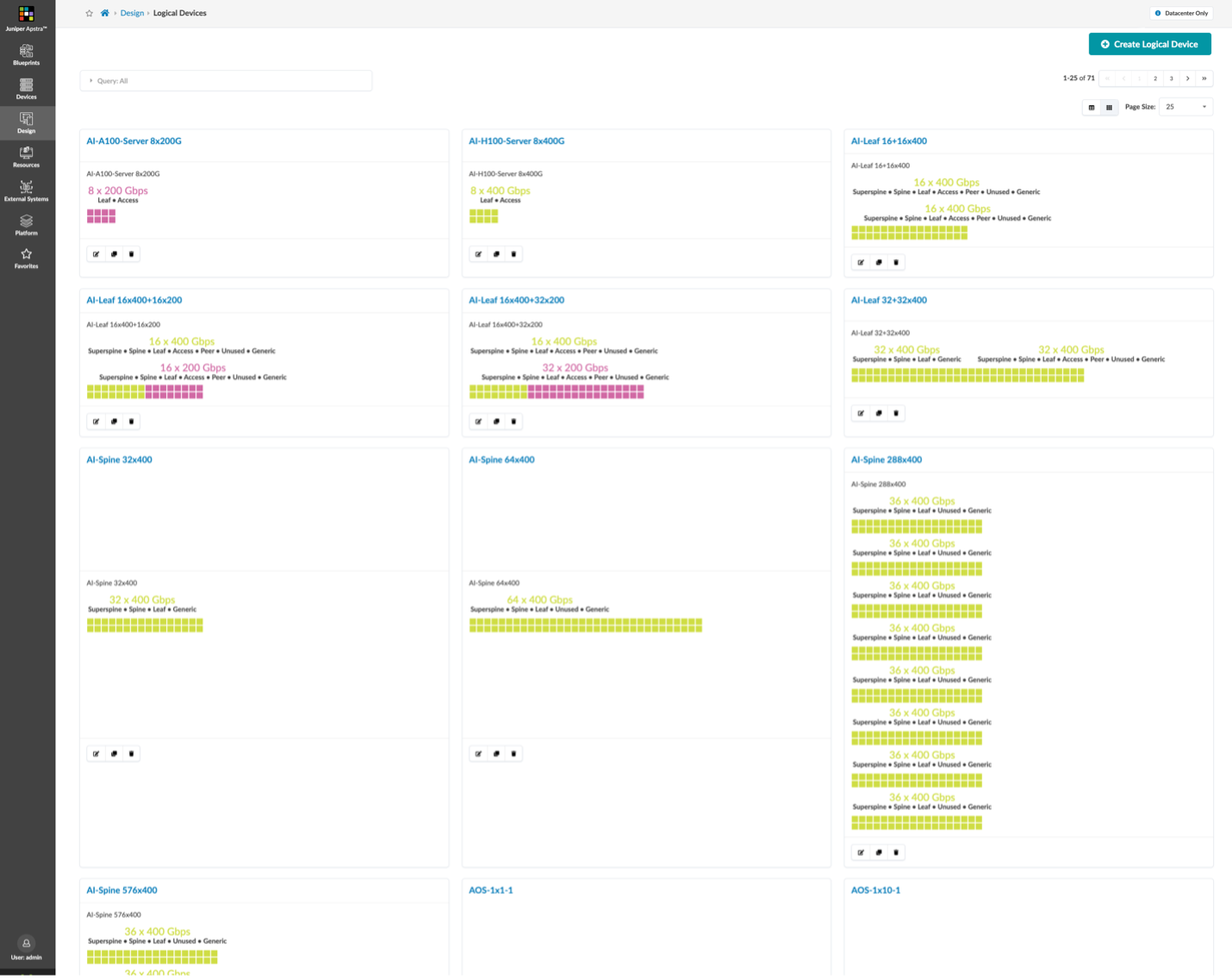
In this example, we’ve modelled the stripe grouping of servers that would connect into a collection of eight leafs as Apstra “Racks”.
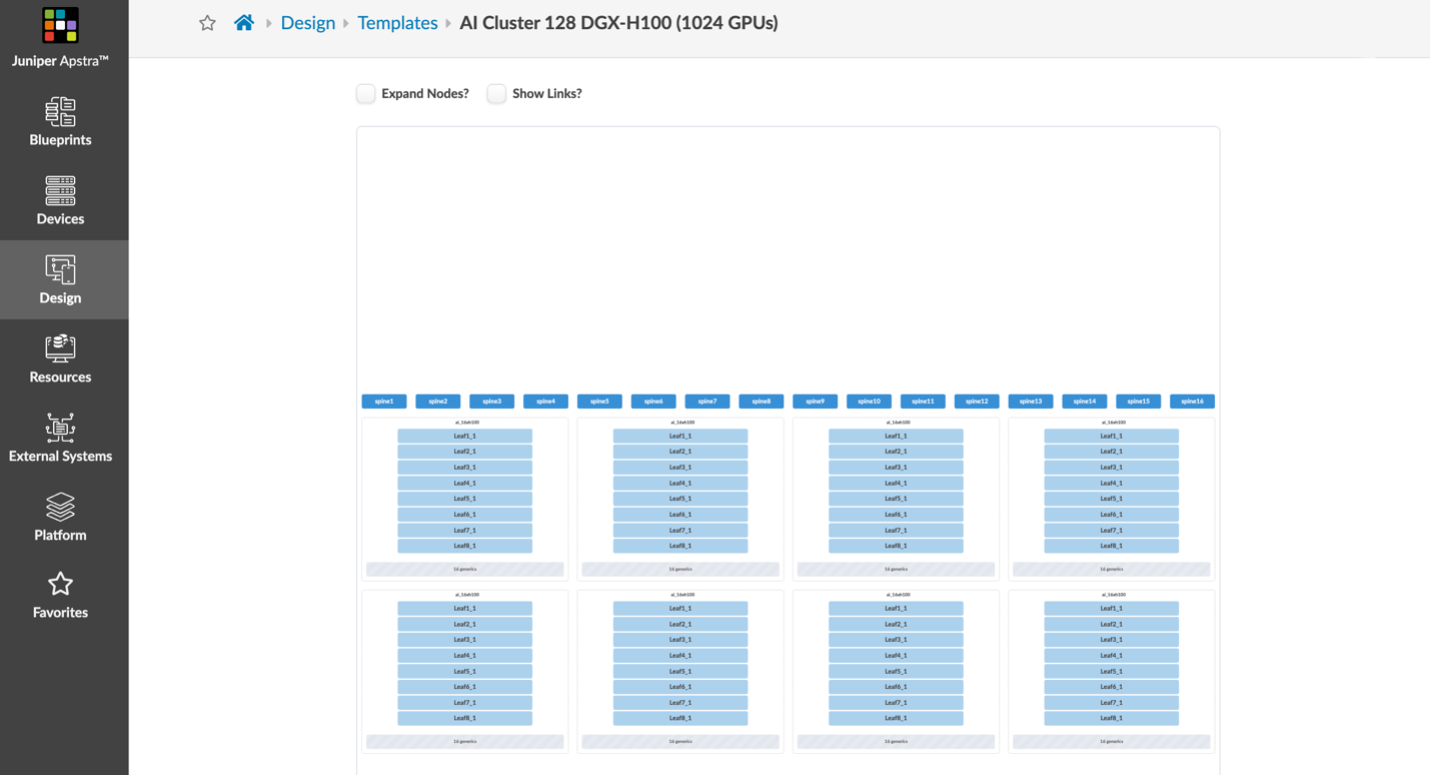
And finally, in Figures 3 & 4 above, we’ve modelled some example network fabrics based on our best practice recommendations to use QFX5220 leaf switches and PTX10000 chassis-based spine switches for their 400GE high radix, which keeps larger fabrics flatter with 2 layers instead of resorting to 3+ layers in 5-stage or larger Clos topologies. In one example template, we connect over 9000 GPUs in a 2-layer spine-leaf topology.
More to Come on AI Data Center Fabrics
You may expect that a blog from Juniper is going to espouse that the network is the key to unlocking dexterity in your AI clusters, and it is, to a large degree. Any distributed workloads depend on the network. But that’s true in spades when it comes to AI training: the network must not be a bottleneck to GPU performance and training job completion time, as pricey compute is what drives the overall cost of an AI data center.
Stay tuned for our point of view (POV) document where we’ll dig into Juniper’s comprehensive portfolio to ensure high-performance AI clusters, our commitment to openness and our experience-first operations approach.
To find out more about rail-optimized designs, read NVIDIA’s blog. To see how easy Terraforming Apstra is for the above, and how to apply all the above examples and more into your own Apstra instance or free trial in Apstra Cloud Labs, visit this GitHub repository. And we’ll have more blogs on automating AI clusters using Apstra where we’ll showcase how to simplify load balancing, congestion management and observability for the traffic profiles particular to model training environments.
With Apstra intent-based operations and AIOps, Juniper is helping assure a great network experience for all kinds of inference and training workloads as enterprises explore new possibilities with AI.
Watch the demo below to learn more about automating AI cluster network design with Juniper Apstra and Terraform. Read part 2 of this blog series here.


