Im Januar 2024 führte Juniper die KI-native Netzwerkplattform ein, um die richtigen Daten über die richtige Infrastruktur zu nutzen und die richtigen Reaktionen zu liefern, damit Benutzern und Betreibern eine optimale Erfahrung geboten wird. Juniper nutzt KI für einen simplifizierten Unternehmensbetrieb (AI for Networking) und für KI optimiertes Ethernet, um den KI-Workload und die GPU-Performance (Networking for AI) zu verbessern, und erfüllt so das Kundenversprechen „Experience-first Networking“.
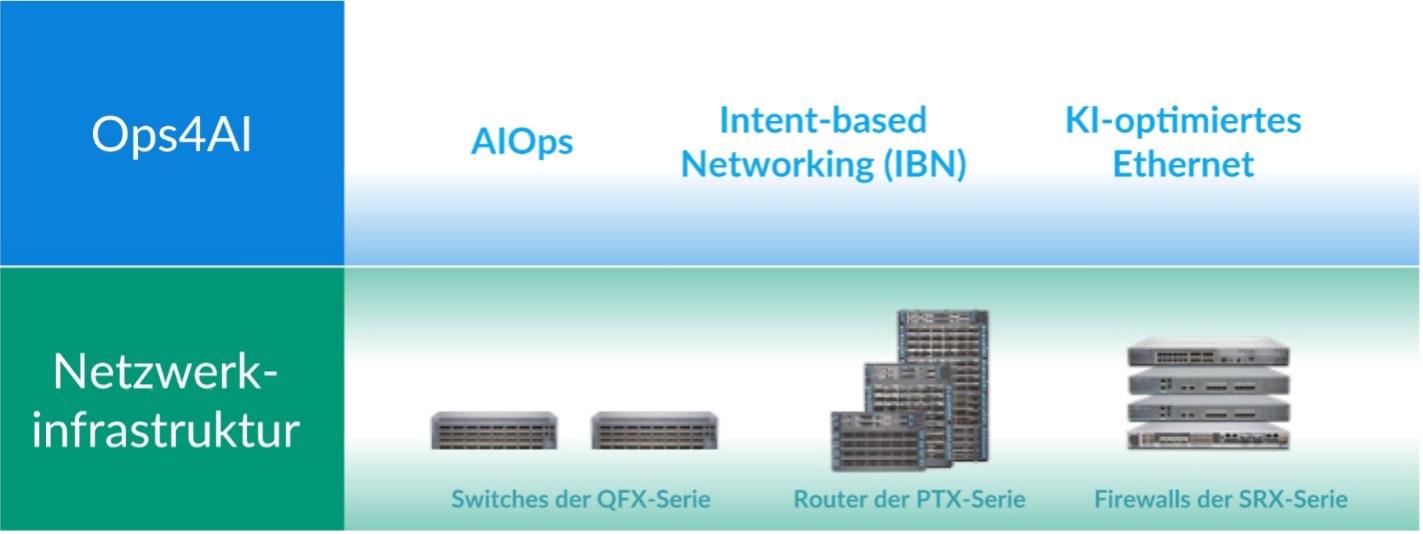
Aufbauend auf unserer langjährigen Erfahrung in der Bereitstellung einer hochleistungsfähigen und sicheren Datencenter-Netzwerkinfrastruktur, die aus Switches der QFX-Serie, Router der PTX-Serie und SRX-Firewalls besteht, erweitert Juniper unsere KI-nativen Unternehmensnetzwerke und bietet Kunden so umfassende Datencenter-Lösungen mehrerer Anbieter. Die bedeutenden Verbesserungen unserer neuen Lösung Ops4AI bieten den Kunden einen erheblichen Mehrwert. Ops4AI umfasst eine einzigartige Kombination aus den folgenden Juniper Networks Komponenten:
- AIOps im Datencenter basiert auf dem virtuellen Netzwerkassistenten Marvis
- Intent-basierte Automatisierung über das anbieterunabhängige Datencenter-Fabric-Management von Juniper Apstra
- für KI optimiertes Ethernet, einschließlich RoCEv2 für IPv4/v6, Überlastungsmanagement, effizientes Load-Balancing und Telemetrie
Zusammen beschleunigt Ops4AI die Time-to-Value hochleistungsfähiger KI-Datencenter, senkt die Betriebskosten und sorgt für reibungslose Prozesse. Dank zusätzlicher neuer Erweiterungen wird die Lösung noch besser: Ein neues Juniper Ops4AI Lab mehrerer Anbieter, das Kunden zum Testen von Open-Source- und privaten KI-Modellen zur Verfügung steht; validierte Designs von Juniper, die Networking for AI-Konfigurationen mit Juniper, Nvidia, Broadcom, Intel, Weka und weiteren Partnern ermöglichen; und Verbesserungen der Junos-Software und Apstra für KI-optimierte Datencenter-Netzwerke – ein Hauptaugenmerk dieses Blogs.
Sehen wir uns die neuen Verbesserungen der Junos®-Software und Juniper Apstra an. Diese umfassen:
Fabric Autotuning for AI
Remote Dynamic Memory Access (RDMA) von GPUs treibt den Datenverkehr in KI-Netzwerken stark an. Trotz Techniken zur Vermeidung von Überlastung wie Load-Balancing kann es zu Überlastung kommen (z. B. durch Datenverkehr von mehreren GPUs, die beim letzten Hop-Switch durch einen einzigen GPU treten). In diesem Fall nutzen Kunden Techniken zur Vermeidung von Überlastung wie Data Center Quantified Congestion Notification (DCQCN). DCQCN verwendet Funktionen wie Explicit Congestion Notification (ECN) und Priority-Based Flow Control (PFC), um die Parametereinstellungen zu kalkulieren und zu konfigurieren und so über alle Switches hinweg die beste Performance für jede Warteschlange pro Anschluss zu gewährleisten. Diese Einstellungen manuell für Tausende von Warteschlangen über alle Switches hinweg vorzunehmen ist mühsam und schwierig.
Deshalb erfasst Apstra regelmäßig Telemetriedaten jeder dieser Warteschlangen pro Anschluss. Diese Telemetriedaten werden verwendet, um die besten ECN- und PFC-Parametereinstellungen für jede Warteschlange pro Anschluss zu kalkulieren. Durch Closed-Loop-Automatisierung werden in allen Switches des Netzwerks die optimalen Einstellungen konfiguriert.
Diese Lösung legt die besten Einstellungen zur Überlastungskontrolle fest, simplifiziert dadurch die betrieblichen Abläufe erheblich und minimiert die Latenz und Zeit, die für die Ausführung von Jobs benötigt wird. Unsere Kunden investieren so stark in KI-Infrastrukturen, dass wir diese Funktionen in Juniper Apstra ohne zusätzliche Kosten anbieten. Sehen Sie sich eine Demo des letzten Cloud Field Day an, um die Funktionen aus nächster Nähe zu erleben. Wir haben die Anwendung auch auf GitHub hochgeladen.
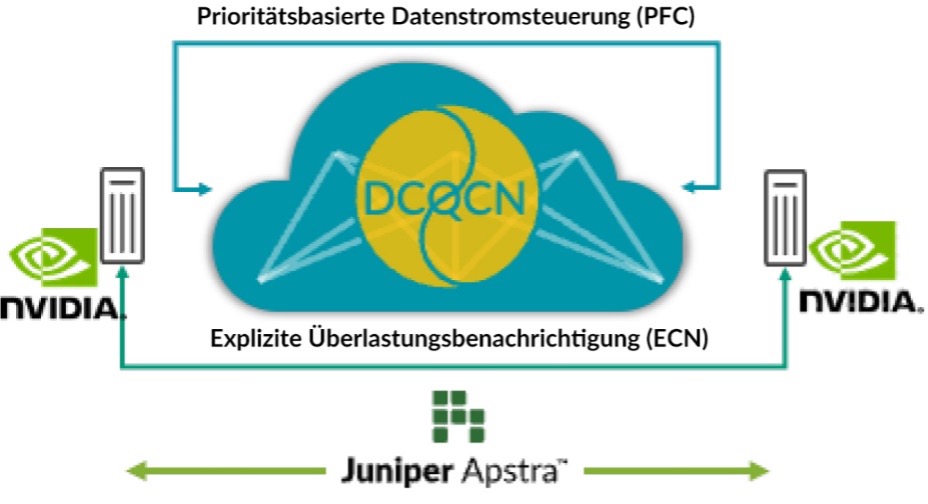
Abbildung 1: Fabric Autotuning for AI
Globales Load-Balancing
Der KI-Netwerkdatenverkehr zeichnet sich durch einzigartige Eigenschaften aus. Er wird meistens durch RDMA-Datenverkehr von GPUs angetrieben, was zu einer hohen Bandbreite und weniger, aber größeren Datenströmen führt (häufig auch als Elephant Flows bezeichnet). Das Ergebnis ist ein statisches Load-Balancing, das auf einem Hash mit 5 Tupeln basiert und nicht gut funktioniert. Mehrere Elephant Flows werden derselben Verbindung zugeordnet und führen zu Überlastung. Dies führt zu langsameren JCTs – eine Katastrophe für große Investitionen in GPUs.
Um dieses Problem zu beheben, steht dynamisches Load-Balancing (DLB) zur Verfügung. DLB berücksichtigt den Uplink-Status im lokalen Switch.
Verglichen mit herkömmlichem, statischem Load-Balancing verbessert DLB die Fabric-Bandbreitennutzung erheblich. Eine der Einschränkungen von DLB besteht jedoch darin, dass es nur die Qualität der lokalen Verbindungen verfolgt, anstatt die Qualität des gesamten Pfads vom Eingangs- bis zum Ausgangsknoten. Nehmen wir folgendes Beispiel: Server 1 und Server 2 versuchen mit CLOS-Topologie jeweils Daten namens „flow-1“ und „flow-2“ zu senden. Wenn Sie DLB verwenden, kennt leaf-1 nur die lokale Verbindungsauslastung und trifft seine Entscheidungen ausschließlich aufgrund der lokalen Switch-Qualitätstabelle, wobei die lokalen Verbindungen in perfektem Zustand sein können. Mit GLB jedoch können Sie die Qualität des gesamten Pfads nachvollziehen, wo Überlastungen innerhalb des SpineLeaf-Levels auftreten.
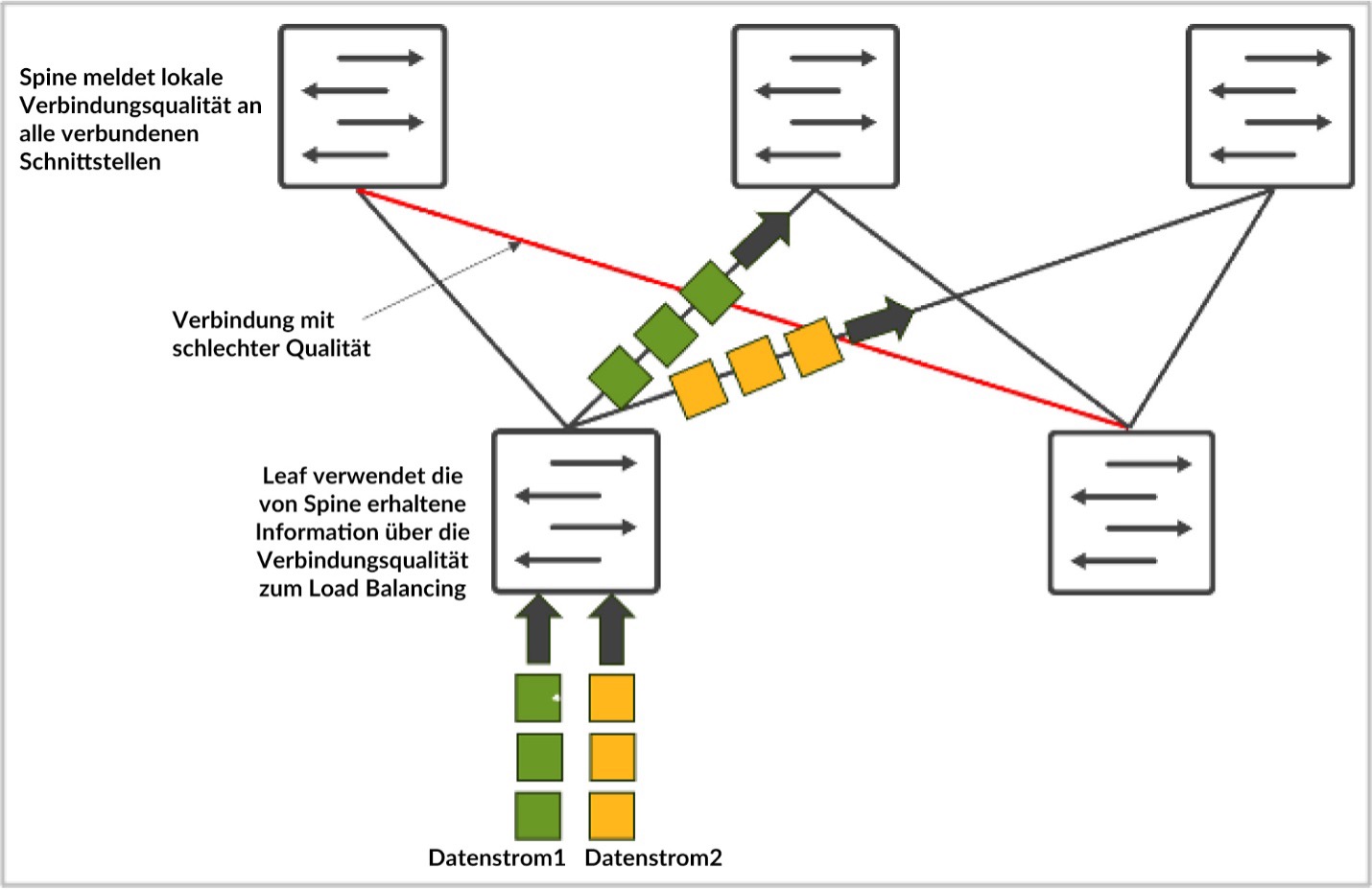
Abbildung 2: Load-Balancing bei Datenströmen
Ähnlich wie bei Google Maps basiert die gewählte Route auf einer End-to-End-Ansicht.
Diese Funktion wählt den optimalen Netzwerkpfad aus und bietet eine geringere Latenz, eine bessere Nutzung und schnellere JCTs. Aus Sicht des KI-Workloads führt dies zu einer besseren KI-Workload-Performance und einer besseren Nutzung von kostspieligen GPUs.
End-to-End-Visibilität vom Netzwerk bis zu SmartNICs
Heute können Admins allein durch die Beobachtung der Netzwerk-Switches herausfinden, wo es zu Überlastungen kommt. Sie sehen aber nicht, welche Endgeräte (im Fall von KI-Datencentern: GPUs) von den Überlastungen betroffen sind. Dies führt zur erschwerten Erkennung und Behebung von Performance-Problemen. In einer Umgebung mit mehreren Trainingsjobs ist es unmöglich, anhand der Switch-Telemetrie herauszufinden, welche Trainingsjobs aufgrund von Überlastung verlangsamt wurden, ohne die NIC RoCE v2-Statistiken aller Server manuell zu überprüfen, was nicht praktikabel ist.
Die Integration der umfangreichen RoCE v2-Streaming-Telemetrie von den SmartNICs der KI-Server zu Juniper Apstra und die Korrelation der vorhandenen Netzwerk-Switch-Telemetrie verbessert die Visibilität und die Fehlerbehebung bei Workflows erheblich, wenn Leistungsprobleme auftreten. Diese Korrelation ermöglicht einen ganzheitlicheren Blick auf das Netzwerk und ein besseres Verständnis der Beziehungen zwischen KI-Servern und dem Netzwerkverhalten. Die Echtzeitdaten bieten Einblicke in Netzwerkleistung, Datenverkehrsmuster, potenzielle Überlastungspunkte und betroffene Endpunkte und helfen, Leistungsengpässe und Anomalien zu erkennen.
Diese Fähigkeit verbessert die Netzwerküberwachung, simplifiziert die Fehlerbehebung bei Performance-Problemen und trägt zur Verbesserung der Gesamtleistung des Netzwerks bei, indem geschlossene Maßnahmen getroffen werden. So kann beispielsweise die Überwachung von Paketen außerhalb der Reihenfolge in den SmartNICs dazu beitragen, die Parameter der intelligenten Load-Balancing-Funktion des Switches zu optimieren. Die End-to-End-Visibilität kann so den Benutzern helfen, die KI-Infrastruktur mit maximaler Leistung zu betreiben.

Abbildung 3: End-to-End-Visibilität vom Netzwerk bis zu SmartNICs
Nehmen Sie für weitere Informationen an unserem Online-Event „Seize the AI Moment“ am 23. Juli teil, wo wir ein hochkarätiges Team von Kunden von Juniper und Branchengrößen begrüßen dürfen, die über ihre Erfahrungen in der sich schnell entwickelnden Welt der Infrastruktur von KI-Datencentern sprechen.
Erklärung zur Produktausrichtung. Juniper Networks kann Informationen über die Entwicklung und Planung von zukünftigen Produkten, Funktionen oder Verbesserungen offenlegen. Dies wird auch als Erklärung zur Produktausrichtung oder „Plan of Record“ (POR) bezeichnet. Diese Details basieren auf den aktuellen Entwicklungsvorhaben und Planungen von Juniper. Juniper behält sich das Recht vor, diese Entwicklungsvorhaben und Planungen jederzeit ohne vorherige Ankündigung zu ändern. Soweit nicht in einem konkreten Vertrag aufgeführt, gibt Juniper keine Zusicherungen ab, dass die auf dieser Website, in Präsentationen, Meetings oder Veröffentlichungen präsentierten Produkte, Funktionen oder Verbesserungen eingeführt werden, und übernimmt diesbezüglich auch keine Haftung. Kaufentscheidungen von Dritten sollten nicht auf diesem POR basiert sein, und Käufe sind nicht abhängig davon, dass Juniper Networks die auf dieser Website, einer Präsentation, einem Meeting oder einer Veröffentlichung beschriebenen Funktionen oder Funktionalitäten bereitstellt.