





















2024 年 1 月,瞻博网络推出了人工智能原生网络平台,通过合适的基础架构利用正确的数据,提供最佳用户体验与运维人员体验所需的正确响应。通过使用 AI 来简化网络运维 (AI for Networking),并使用经过 AI 优化的以太网交换矩阵来改进 AI 工作负载和 GPU 性能 (Networking for AI),瞻博网络正在兑现向客户提供体验至上网络的不变承诺。

瞻博网络在提供高性能安全数据中心基础架构方面拥有悠久的历史,当中包括 QFX 交换机、PTX 路由器和 SRX 防火墙,为此我们自豪地宣布,我们的人工智能原生网络架构扩展现已推出,能够为客户提供支持多供应商运维的端到端 AI 数据中心。全新的 Ops4AI 解决方案提供极具影响力的增强功能,能够进一步为客户带来卓越价值。Ops4AI 包括以下瞻博网络组件的独特组合:
- 基于 Marvis 虚拟网络助手构建的数据中心 AIOps
- 通过 Juniper Apstra 多供应商数据中心交换矩阵管理实现基于意图的自动化
- 经过 AI 优化的以太网功能,包括 RoCEv2 for IPv4/v6、拥塞管理、高效负载平衡和遥测
通过对上述组件进行整合,Ops4AI 能够助力高性能 AI 数据中心加速实现价值,同时降低运维成本并简化流程。现在,随着以下几项增强功能的加入,这款解决方案已然变得更加出色:面向客户开放的全新多供应商 Juniper Ops4AI Lab,用于测试开源和私有 AI 模型及工作负载;采用瞻博网络、Nvidia、Broadcom、Intel、Weka 及其他合作伙伴技术的瞻博网络验证设计,可为 Networking for AI 提供保证;以及经过 AI 优化的数据中心网络所适用的 Junos 软件和 Apstra 增强功能——这也是本篇博客文章的主要关注点。
让我们来看一下针对 Junos® 软件和 Juniper Apstra 推出的全新增强功能。这些功能包括:
AI 交换矩阵自动调整
GPU 的远程动态内存访问 (RDMA) 在 AI 网络中驱动着巨大的网络流量。尽管会采用多种拥塞避免技术,如负载平衡,但拥塞仍时有发生(例如,多个 GPU 将数据传输至最后一个跃点交换机的同一个 GPU,就会造成拥塞)。发生这种情况时,客户可以使用拥塞控制技术,如数据中心量化拥塞通知 (DCQCN)。DCQCN 使用多种功能,如显式拥塞通知 (ECN) 和基于优先级的流控制 (PFC),来计算和配置参数设置,以便在所有交换机每个端口的每个队列上获得最佳性能。在所有交换机的数千个队列中手动设置这些参数既困难又繁琐。
为了解决这一难题,Apstra 会定期从每个端口的每个队列中收集遥测数据。这些遥测信息会用于计算每个端口的每个队列的最佳 ECN 和 PFC 参数设置。利用闭环自动化,可以在网络中的所有交换机上配置最佳设置。
这款解决方案提供最佳的拥塞控制设置,可显著简化运维、降低延迟并缩短作业完成时间 (JCT)。我们的客户在 AI 基础架构上进行了大量投入,这也让我们得以在 Juniper Apstra 中免费提供这些功能。观看最新的 Cloud Field Day 演示,详细了解这些功能的工作原理。我们还将此应用上传到了 GitHub。

图 1:AI 交换矩阵自动调整
全局负载平衡
AI 网络流量具有独特的特性。这些流量主要是由 GPU 产生的 RDMA 流量所驱动,会导致占用大量带宽,流数虽然会减少,但单个流都比较大(通常称为“大象流”)。因此,基于五元组哈希的静态负载平衡效果不佳。多个“大象流”会映射到同一条链路并造成拥塞。这会导致更长的 JCT,对大规模 GPU 投资来说极具破坏性。
想要解决这一难题,可以采用动态负载平衡 (DLB)。DLB 会考虑本地交换机上的上行链路状态。
与传统的静态负载平衡相比,DLB 可以显著增强交换矩阵带宽利用率。但是,DLB 也有局限性,其中一项便是仅跟踪本地链路的质量,而不是了解从入口节点到出口节点的完整路径质量。假设我们有一个 CLOS 拓扑结构,服务器 1 和服务器 2 都在尝试分别发送名为 flow-1 和 flow-2 的数据流。如果采用 DLB,leaf-1 只知道本地链路的使用情况,并仅基于本地交换机质量表做出决策,因此本地链路可能处于完美状态。但是,如果使用 GLB,则可了解整个路径的质量,包括在主干-分叶层级中出现的拥塞问题。
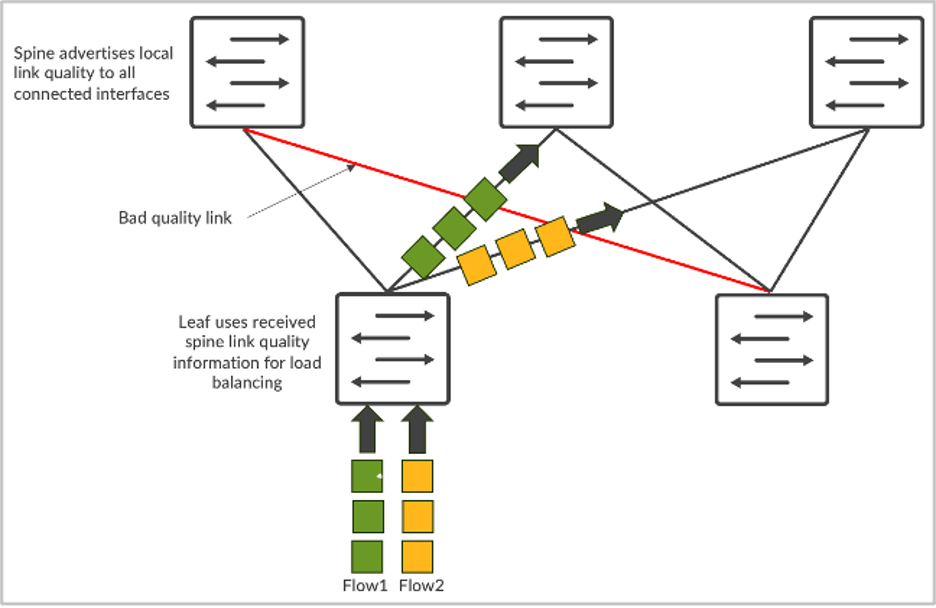
图 2:流负载平衡
这类似于 Google Maps,所选路线基于端到端的视图。
此功能会选择最佳网络路径,并提供更低的延迟、更高的网络利用率和更快的 JCT。从 AI 工作负载的角度来看,这可以带来更佳的 AI 工作负载性能,让昂贵的 GPU 更有效率。
从网络到 SmartNIC 的端到端可见性
如今,管理员仅通过观察网络交换机就可以发现拥塞发生的位置。但是他们无法看到哪些端点(如果使用 AI 数据中心,则是 GPU)受到拥塞的影响。这就导致在识别和解决性能问题方面存在挑战。在多重训练作业环境中,仅通过查看交换机遥测数据,而不手动检查所有服务器上的 NIC RoCE v2 统计信息,就不可能确定哪些训练作业是因拥塞而变慢。但是,手动检查所有这些统计信息非常不切实际。
为了解决这个问题,可将 AI 服务器 SmartNIC 丰富的 RoCE v2 流式遥测数据与 Juniper Apstra 集成,并与现有的网络交换机遥测数据进行关联,从而大幅增强在出现性能问题时的观察能力和调试工作流程。这种关联能够带来更全面的网络视图,从而更好地了解 AI 服务器与网络行为之间的关系。通过实时数据,可以深入了解网络性能、流量模式、潜在拥塞点和受影响的端点,有助于识别性能瓶颈和异常情况。
这项功能可以增强网络观察能力,简化性能问题的调试,并通过采取闭环行动帮助提高整体网络性能。例如,在 SmartNIC 中监控乱序数据包可以帮助调整交换机上智能负载平衡功能的参数。因此,端到端的可见性可以帮助用户以最高性能运行 AI 基础架构。
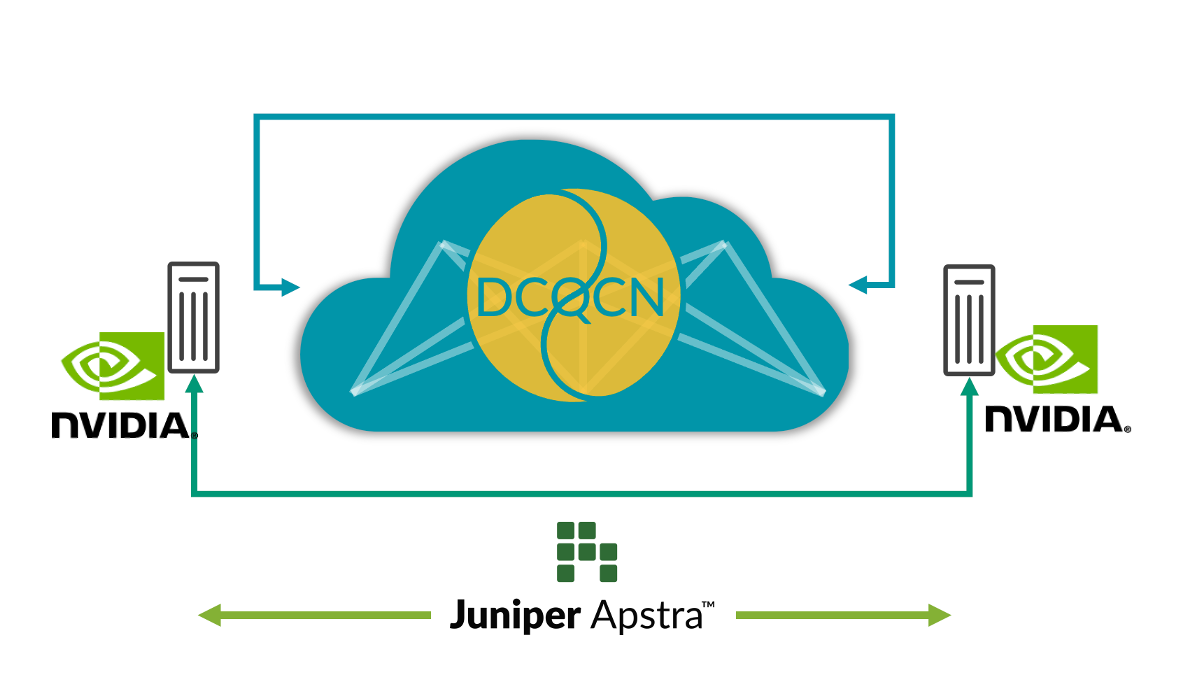
图 3:从网络到 SmartNIC 的端到端可见性
如需了解更多信息,欢迎参加我们于 7 月 23 日举办的“把握 AI 机遇”线上活动。届时,我们将邀请瞻博网络的客户和业内知名人士组成全明星阵容,共同探讨在快速发展的 AI 数据中心基础架构领域中所积累的成功经验。
产品方向说明。瞻博网络可能会披露与未来产品、功能或增强功能的开发和计划相关的信息,即产品方向说明或计划记录(简称“POR”)。 提供的相关细节基于瞻博网络目前的开发工作和计划。瞻博网络可自行决定是否更改这些开发工作和计划,恕不另行通知。除非可能在有约束力的协议中已阐明,否则瞻博网络不会对本网站、演示、会议或出版物中描述的产品、功能或增强功能的介绍做出任何保证或是承担任何责任;对于因依赖 POR 而造成的任何损失,瞻博网络概不负责。 第三方的采购决策不应基于本 POR,任何采购也都不应依赖瞻博网络提供本网站、演示、会议或出版物所述的任何特性或功能。


