In januari 2024 introduceerde Juniper het platform voor AI-native netwerken voor het gebruik van de juiste gegevens via de juiste infrastructuur. Hierdoor kunnen de juiste acties worden ondernomen voor het creëren van optimale gebruikers- en beheerderservaringen. Door het gebruik van AI voor vereenvoudigde netwerkactiviteiten (AI for Networking), en AI-geoptimaliseerde ethernet-fabrics voor verbeterde AI-workload- en GPU-prestaties (Networking for AI), komt Juniper diens belofte aan klanten na als het gaat om experience-first netwerken.
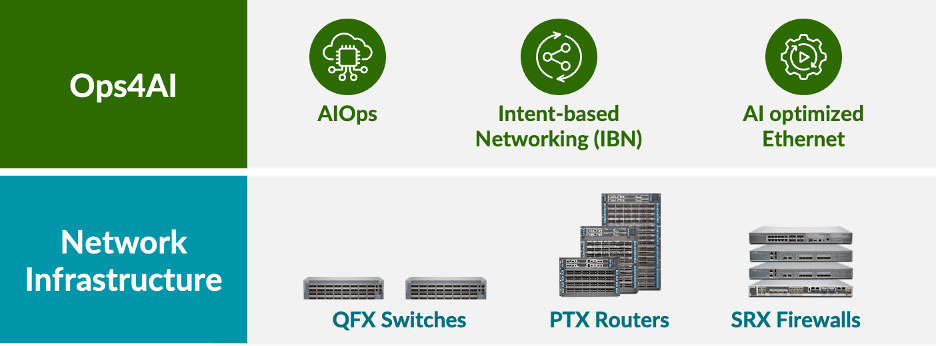
We bouwen voort op onze jarenlange ervaring in het leveren van hoogwaardige infrastructuur voor veilige datacenternetwerken, bestaande uit QFX-switches, PTX-routers en SRX-firewalls. Juniper kondigt dan ook met trots aan dat onze architectuur voor AI-native netwerken wordt uitgebreid om klanten end-to-end activiteiten met meerdere leveranciers te kunnen bieden voor AI-datacenters. Onze nieuwe oplossing, Ops4AI, biedt belangrijke verbeteringen die klanten aanzienlijke meerwaarde zullen opleveren. Ops4AI bevat een unieke combinatie van de volgende Juniper Networks-componenten:
- AIOps in het datacenter gebaseerd op de Marvis virtuele netwerkassistent
- Op intentie gebaseerde automatisering via Juniper Apstra-beheer van datacenterfabric met meerdere leveranciers
- AI-geoptimaliseerde ethernet-mogelijkheden, waaronder RoCEv2 voor IPv4/v6, congestiebeheer, efficiënte loadbalancing en telemetrie
Samen zorgt Ops4AI voor een versnelling van de time-to-value van hoogwaardige AI-datacenters, waarbij tegelijkertijd de operationele kosten worden verlaagd en processen worden gestroomlijnd. En nu wordt de oplossing nog beter dankzij een aantal nieuwe verbeteringen: Een nieuw Juniper Ops4AI-lab met meerdere leveranciers, dat toegankelijk is voor klanten om open source- en private AI-modellen en workloads te testen; Juniper gevalideerde ontwerpen die netwerken voor AI-configuraties mogelijk maken met behulp van Juniper, Nvidia, Broadcom, Intel, Weka en andere partners; en verbeteringen aan de Junos-software en Apstra voor AI-geoptimaliseerd datacenternetwerken. Dit blog is met name hierop gericht.
Laten we eens kijken naar de nieuwe verbeteringen in de Junos®-software en Juniper Apstra. Deze omvatten:
Fabric-autotuning voor AI
Remote Dynamic Memory Access (RDMA) vanuit GPU’s zorgt voor een enorme hoeveelheid netwerkverkeer in AI-netwerken. Ondanks technieken om congestie te vermijden, zoals loadbalancing, zijn er situaties waarin er congestie optreedt (bijv. als verkeer vanuit meerdere GPU’s naar één GPU gaat bij de switch voor de laatste stap). Wanneer dit plaatsvindt, gebruiken klanten technieken voor congestiebeheer, zoals Data Center Quantified Congestion Notification (DCQCN). DCQCN maakt gebruik van functies als expliciete melding van congestie (Explicit Congestion Notification, ECN) en datastroombeheer op basis van prioriteit (Priority-Based Flow Control, PFC). Hiermee worden parameterinstellingen berekend en geconfigureerd om de beste prestaties te behalen voor elke wachtrij, voor elke poort en via alle switches. Het is ingewikkeld en omslachtig om deze instellingen handmatig aan te passen voor duizenden wachtrijen en switches.
Om dit probleem op te lossen, verzamelt Apstra regelmatig telemetrische gegevens vanuit elke wachtrij voor elke poort. Deze telemetrische informatie wordt gebruikt om de optimale ECN- en PFC-parameterinstellingen te berekenen voor elke wachtrij en elke poort. Met behulp van closed-loop automatisering worden de optimale instellingen geconfigureerd op alle switches in het netwerk.
Deze oplossing biedt de optimale instellingen voor congestiebeheer, waardoor de activiteiten aanzienlijk worden vereenvoudigd en er sprake is van lagere latentie en een kortere voltooiingstijd voor taken (job completion times, JCT’s). Onze klanten investeren al dusdanig veel in AI-infrastructuur, dat we deze functies nu zonder extra kosten beschikbaar hebben gemaakt in Juniper Apstra. Bekijk een demo van de recentste Cloud Field Day om van dichtbij te zien hoe ze functioneren. We hebben deze applicatie ook geüpload naar GitHub.
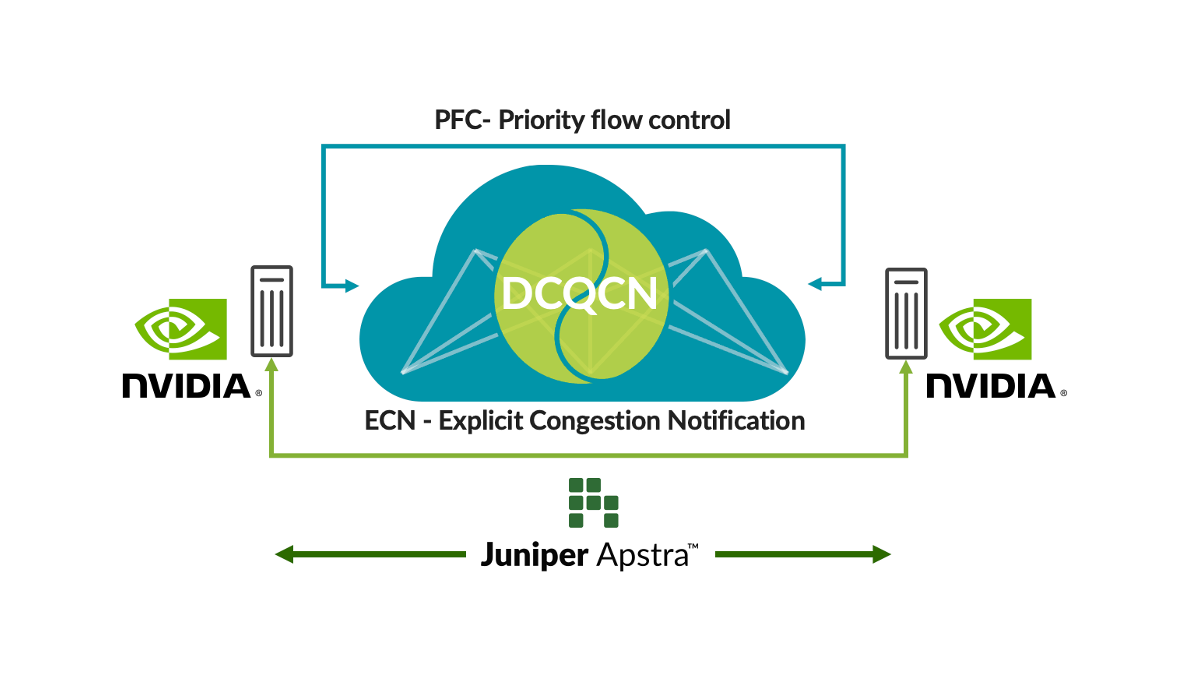
Afbeelding 1: Fabric-autotuning voor AI
Globale loadbalancing
AI-netwerkverkeer heeft unieke kenmerken. Het wordt voornamelijk aangedreven door RDMA-verkeer vanuit GPU’s, wat resulteert in een hoge bandbreedte en minder, maar grotere stromen (vaak olifantstromen genoemd). Als gevolg hiervan werkt statische loadbalancing op basis van hash met 5 tuples niet goed. Meerdere olifantstromen worden naar dezelfde link geleid en veroorzaken congestie. Dit resulteert in tragere JCT’s, wat funest is voor grote GPU-investeringen.
Om dit probleem op te lossen, is er dynamische loadbalancing (DLB) beschikbaar. DLB houdt rekening met de uplink-status op de lokale switch.
Vergeleken met traditionele statische loadbalancing verbetert DLB het gebruik van de fabricbandbreedte aanzienlijk. Maar een beperking van DLB is dat het alleen de kwaliteit van lokale links volgt en dus geen inzicht heeft in de kwaliteit van het gehele pad van ingangs- tot uitgangsknooppunt. Stel dat we een CLOS-topologie hebben, waarbij server 1 en server 2 beide proberen allerlei gegevens te verzenden die respectievelijk stroom-1 en stroom-2 worden genoemd. In het geval van DLB kent leaf-1 alleen het gebruik van de lokale links en neemt deze alleen beslissingen op basis van de kwaliteitstabel voor lokale switches, waarbij de lokale links in perfecte staat kunnen verkeren. Als u echter GLB gebruikt, hebt u inzicht in de gehele padkwaliteit en ziet u waar congestieproblemen zich voordoen op het spine-leaf-niveau.
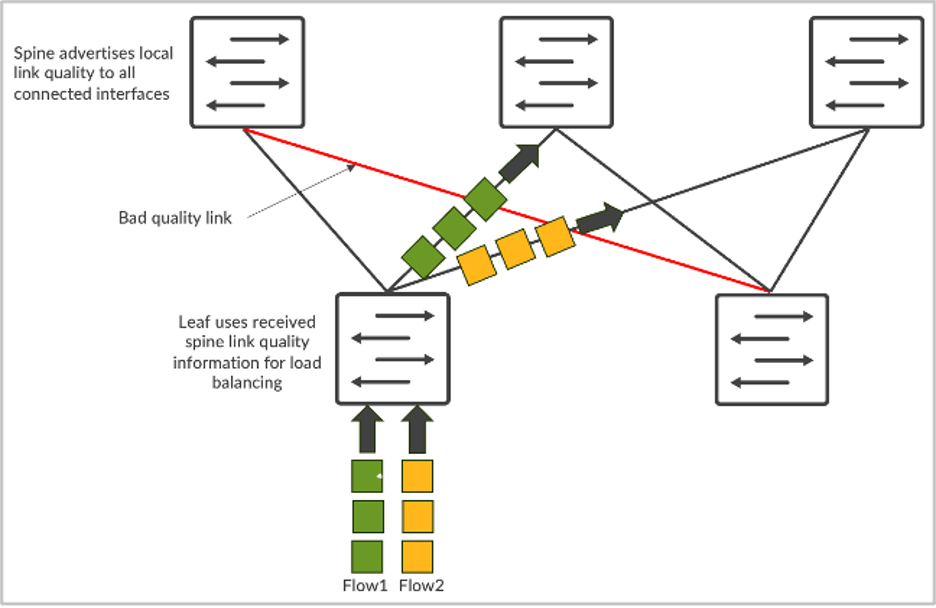
Afbeelding 2: Loadbalancing van stromen
Het is vergelijkbaar met Google Maps, waarbij de geselecteerde route is gebaseerd op een end-to-end weergave.
Met deze functie wordt het optimale netwerkpad geselecteerd en worden een lagere latentie, een beter netwerkgebruik en snellere JCT’s bereikt. Vanuit het perspectief van de AI-workload resulteert dit in betere AI-workloadprestaties en een intensiever gebruik van prijzige GPU’s.
End-to-end zichtbaarheid vanuit netwerk naar SmartNIC’s
Tegenwoordig kunnen beheerders achterhalen waar congestie optreedt door alleen de netwerkswitches te observeren. Ze hebben echter geen zicht op welke eindpunten (GPU’s, in het geval van AI-datacenters) worden getroffen door congestie. Dit brengt uitdagingen met zich mee tijdens het identificeren en oplossen van prestatieproblemen. In een omgeving met meerdere trainingstaken is het onmogelijk om alleen aan de hand van de switchtelemetrie te bepalen welke trainingstaken zijn vertraagd door congestie zonder handmatig de NIC RoCE v2-statistieken op alle servers te controleren. Dit is praktisch gezien niet haalbaar.
Om dit probleem op te lossen, zorgt de integratie van rijke RoCE v2-streamingtelemetrie vanuit de AI Server SmartNIC’s naar Juniper Apstra en het correleren van bestaande netwerkswitchtelemetrie, voor een aanzienlijke verbetering van de waarneembaarheid en het oplossen van prestatieproblemen in workflows. Deze correlatie zorgt voor een meer holistische netwerkbenadering en meer inzicht in de relaties tussen AI-servers en netwerkgedrag. De realtimegegevens bieden inzicht in netwerkprestaties, verkeerspatronen, potentiële congestiepunten en getroffen eindpunten. Hierdoor kunnen prestatieproblemen en -afwijkingen worden opgespoord.
Dankzij deze mogelijkheid wordt de waarneembaarheid van het netwerk verbetert en worden prestatieproblemen eenvoudiger opgelost. Bovendien kunnen de algehele netwerkprestaties worden verbeterd door closed-loop acties te ondernemen. Zo kan het monitoren van ongeordende pakketten bijvoorbeeld helpen bij het afstemmen van de parameters in de functie voor slimme loadbalancing op de switch. Op deze manier kan end-to-end zichtbaarheid gebruikers helpen om de AI-infrastructuur optimaal te laten presteren.
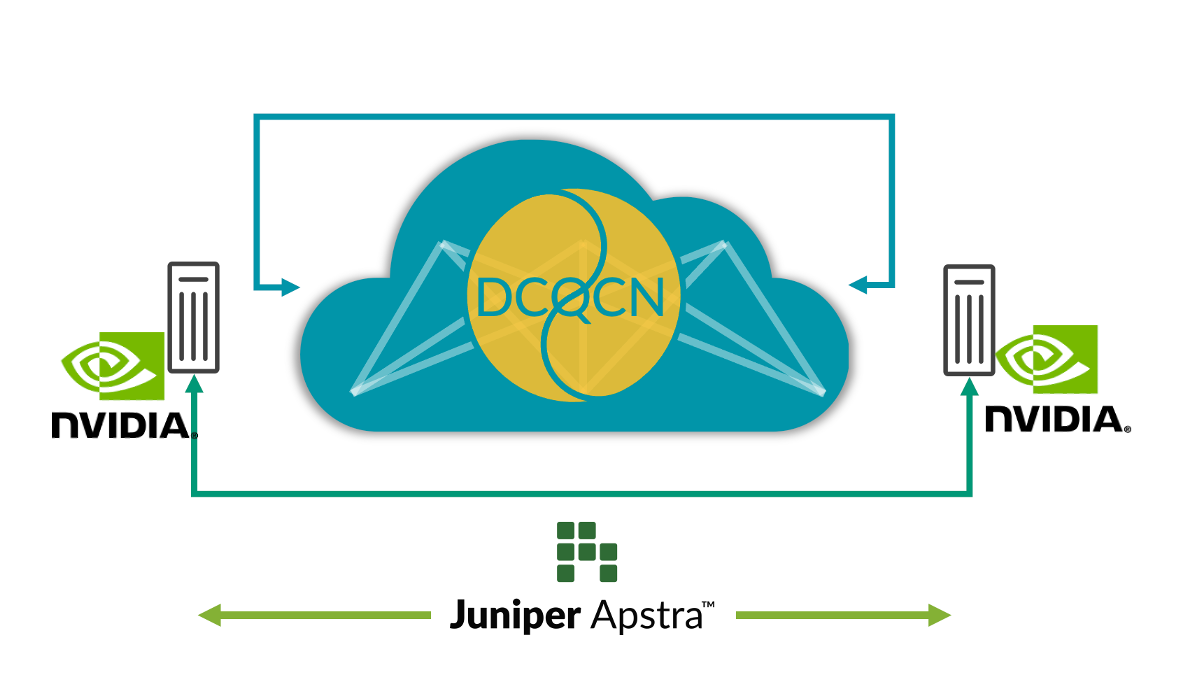
Afbeelding 3: E2E-zichtbaarheid vanuit netwerk naar SmartNIC’s
Voor meer informatie kunt u deelnemen aan ons online evenement ‘Seize the AI Moment’ op 23 juli. Hier komen vele Juniper-klanten en vooraanstaande personen uit de branche praten over wat zij hebben geleerd in de zeer dynamische wereld van AI-datacenterinfrastructuur.
Verklaring over richting productontwikkeling. Juniper Networks kan informatie openbaar maken met betrekking tot de ontwikkeling en de plannen voor toekomstige producten, functies of verbeteringen, bekend als een Verklaring over richting productontwikkeling of Vastgelegd plan (‘POR’). Deze details zijn gebaseerd op de huidige ontwikkelingsinspanningen en plannen van Juniper. Deze ontwikkelingsinspanningen en plannen kunnen naar eigen goeddunken en zonder voorafgaande kennisgeving door Juniper worden gewijzigd. Behalve zoals uiteengezet in een definitieve overeenkomst, geeft Juniper Networks geen garanties en neemt het geen verantwoordelijkheid voor de introductie van producten, functies of verbeteringen die op deze website of in deze presentatie, vergadering of publicatie worden beschreven. Juniper is evenmin aansprakelijk voor enig verlies dat voortvloeit uit het vertrouwen op het POR. Externe aankoopbeslissingen mogen niet worden gebaseerd op dit POR en aankopen zijn niet afhankelijk van de levering door Juniper Networks van enige functie of functionaliteit die wordt beschreven op deze website of in deze presentatie, vergadering of publicatie.