





















A gennaio 2024, Juniper ha introdotto la AI-Native Networking Platform per utilizzare i dati corretti attraverso l’infrastruttura appropriata e fornire le risposte giuste per un’esperienza ottimale di utenti e operatori. Utilizzando l’AI per operazioni di rete semplificate (AI for Networking) e fabric Ethernet ottimizzati per l’AI al fine di migliorare le prestazioni del carico di lavoro AI e della GPU (Networking for AI), Juniper mantiene il suo impegno nei confronti dei clienti per un experience-first networking.
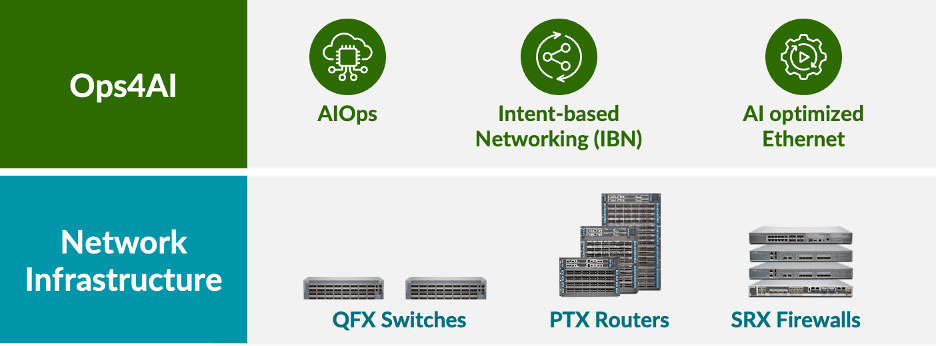
Basandosi sulla sua ricca storia di fornitori di infrastrutture di rete per data center protetti ad alte prestazioni, costituite da switch QFX, router PTX e firewall SRX, Juniper è lieta di annunciare un’estensione della propria architettura AI-Native networking che offre ai clienti operazioni end-to-end e multivendor per i data center AI. La nuova soluzione, Ops4AI, offre miglioramenti di grande impatto che garantiranno ulteriore valore significativo ai clienti. Ops4AI include una combinazione unica dei seguenti componenti Juniper Networks:
- AIOps nel data center basato su Marvis Virtual Network Assistant
- Automazione basata sugli intenti tramite la gestione del fabric del data center multivendor Juniper Apstra
- Funzionalità Ethernet ottimizzate per l’AI, tra cui RoCEv2 per IPv4/v6, controllo della congestione, bilanciamento del carico efficiente e telemetria
Nel complesso, Ops4AI consente una rapida accelerazione del time-to-value dei data center AI ad alte prestazioni, riducendo contemporaneamente i costi operativi e semplificando i processi. E ora la soluzione è ancora più efficace grazie all’aggiunta di numerosi nuovi miglioramenti: un nuovo Juniper Ops4AI Lab multivendor aperto ai clienti per testare modelli e carichi di lavoro di AI open source e privati; design convalidati di Juniper che assicurano il networking per le configurazioni AI utilizzando Juniper, Nvidia, Broadcom, Intel, Weka e altri partner; miglioramenti al software Junos e Apstra per il networking di data center ottimizzati per l’AI, uno degli argomenti principali di questo blog.
Vediamo i nuovi miglioramenti del software Junos® e di Juniper Apstra. Includono:
Ottimizzazione automatica del fabric per l’AI
Il Remote Dynamic Memory Access (RDMA) dalle GPU genera un enorme traffico di rete nelle reti AI. Nonostante le tecniche di prevenzione della congestione come il bilanciamento del carico, esistono situazioni in cui si verifica congestione (ad esempio, traffico da più GPU che va a una singola GPU nell’ultimo hop switch). In questi casi, i clienti utilizzano tecniche di controllo della congestione quali la notifica di congestione quantizzata del data center (DCQCN). DCQCN utilizza funzioni come la notifica esplicita della congestione (ECN) e il controllo del flusso basato sulla priorità (PFC) per calcolare e configurare le impostazioni dei parametri in modo da ottenere le prestazioni migliori per ogni coda per ogni porta su tutti gli switch. L’impostazione manuale di migliaia di code su tutti gli switch è difficile e macchinosa.
Per affrontare questo problema, Apstra raccoglie regolarmente informazioni di telemetria da ciascuna coda su ogni porta. Tali informazioni vengono utilizzate per calcolare le impostazioni ottimali dei parametri ECN ed PFC per ciascuna coda su ogni porta. Utilizzando l’automazione a ciclo chiuso, le impostazioni ottimali vengono configurate su tutti gli switch nella rete.
Questa soluzione offre le impostazioni migliori per il controllo della congestione, semplificando notevolmente le operazioni e riducendo la latenza e i tempi di completamento delle operazioni (JCT). Gli investimenti dei nostri clienti nell’infrastruttura AI sono talmente elevati che abbiamo reso disponibili queste funzionalità in Juniper Apstra senza alcun costo aggiuntivo. Guarda la demo dell’ultimo Cloud Field Day per vedere come funzionano da vicino. Abbiamo anche caricato questa applicazione su GitHub.
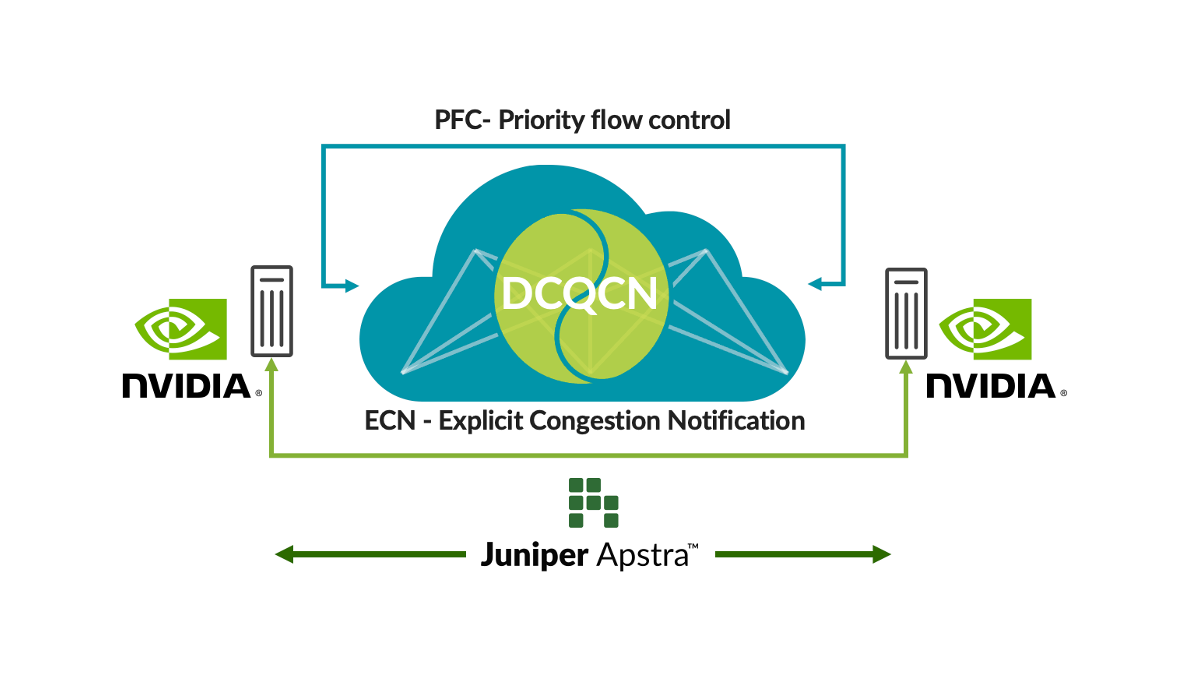
Figura 1: Ottimizzazione automatica del fabric per l’AI
Bilanciamento del carico globale
Il traffico di rete AI ha caratteristiche uniche. Si tratta prevalentemente di traffico RDMA proveniente dalle GPU, che si traduce in una larghezza di banda elevata e in un numero minore di flussi, ma di dimensioni maggiori (spesso detti flussi elefantiaci). Ne consegue che il bilanciamento del carico statico basato sull’hash a 5 tuple non funziona correttamente. Più flussi elefantiaci mappano sullo stesso link e causano congestione. Ciò si traduce in un rallentamento dei tempi di completamento delle operazioni (JCT), che risulta devastante per i grandi investimenti in GPU.
Per risolvere il problema, è disponibile il bilanciamento del carico dinamico (DLB). Il DLB tiene conto dello stato dell’uplink sullo switch locale.
Rispetto al tradizionale bilanciamento del carico statico, il DLB migliora significativamente l’utilizzo della larghezza di banda del fabric. Tuttavia, uno dei limiti del DLB è rappresentato dal fatto che tiene conto solo della qualità dei link locali, anziché comprendere la qualità dell’intero percorso dal nodo di ingress a quello di egress. Supponiamo di avere una topologia CLOS e che il server 1 e il server 2 stiano entrambi cercando di inviare dati chiamati rispettivamente flusso-1 e flusso-2. Nel caso del DLB, leaf-1 conosce solo l’utilizzo dei link locali e prende decisioni basate esclusivamente sulla tabella della qualità dello switch locale, dove i link locali possono essere in perfetto stato. Se invece si utilizza GLB, è possibile comprendere la qualità dell’intero percorso, dove i problemi di congestione sono presenti a livello di spine-leaf.
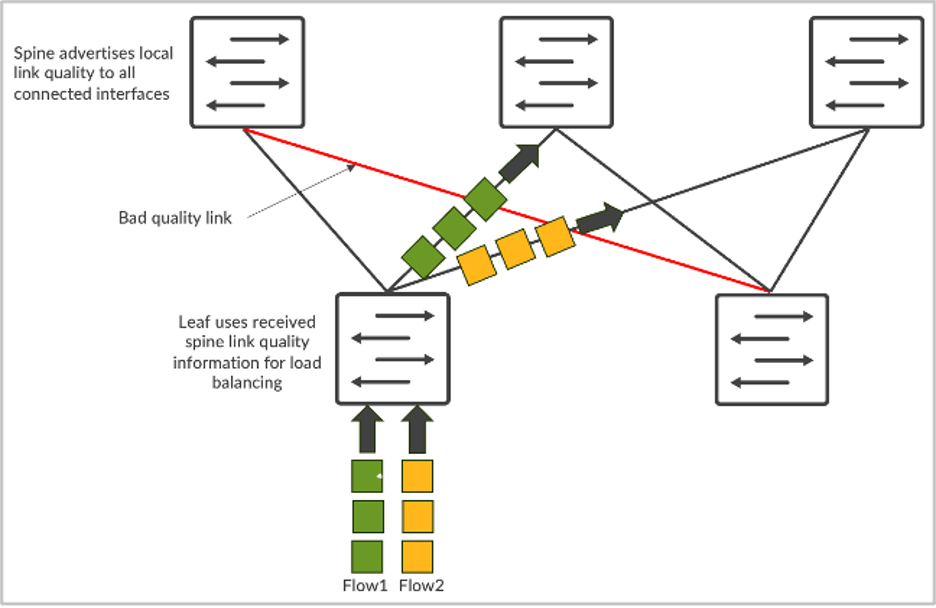
Figura 2: Bilanciamento del carico dei flussi
È come Google Maps, dove il percorso selezionato si basa su una vista end-to-end.
Questa funzionalità seleziona il percorso di rete ottimale e garantisce una latenza inferiore, un migliore utilizzo della rete e tempi di completamento delle operazioni (JCT) più rapidi. Dal punto di vista del carico di lavoro AI, ciò si traduce in migliori prestazioni del carico di lavoro AI e in un maggiore utilizzo delle costose GPU.
Visibilità end-to-end dalla rete alle SmartNIC
Oggi gli amministratori possono individuare i punti di congestione osservando solo gli switch di rete. Ma non hanno alcuna visibilità sugli endpoint (le GPU, nel caso dei data center AI) che risentono della congestione. Questo comporta delle difficoltà nell’identificare e risolvere i problemi di prestazioni. In un ambiente con più lavori di addestramento, è impossibile individuare i lavori di addestramento che sono stati rallentati a causa della congestione solo guardando la telemetria dello switch, senza controllare manualmente tutte le statistiche NIC RoCE v2 su tutti i server, il che non è pratico.
Per affrontare il problema, integrare una ricca telemetria in streaming di RoCE v2 dalle SmartNIC dei server AI a Juniper Apstra e correlare la telemetria degli switch di rete esistente migliora notevolmente l’osservabilità e i flussi di lavoro di debug quando si verificano problemi di prestazioni. Questa correlazione consente una visione più olistica della rete e permette di comprendere meglio le relazioni tra i server AI e i comportamenti della rete. I dati in tempo reale forniscono informazioni su prestazioni della rete, modelli di traffico, potenziali punti di congestione ed endpoint interessati, aiutando a identificare i colli di bottiglia e le anomalie delle prestazioni.
Questa funzionalità migliora l’osservabilità della rete, semplifica il debug dei problemi di prestazioni e contribuisce a migliorare le prestazioni complessive della rete adottando azioni closed-loop. Ad esempio, il monitoraggio dei pacchetti fuori sequenza nelle SmartNIC può aiutare a mettere a punto i parametri della funzione di bilanciamento del carico smart sullo switch. Pertanto, la visibilità end-to-end può aiutare gli utenti a far funzionare l’infrastruttura AI al massimo delle prestazioni.
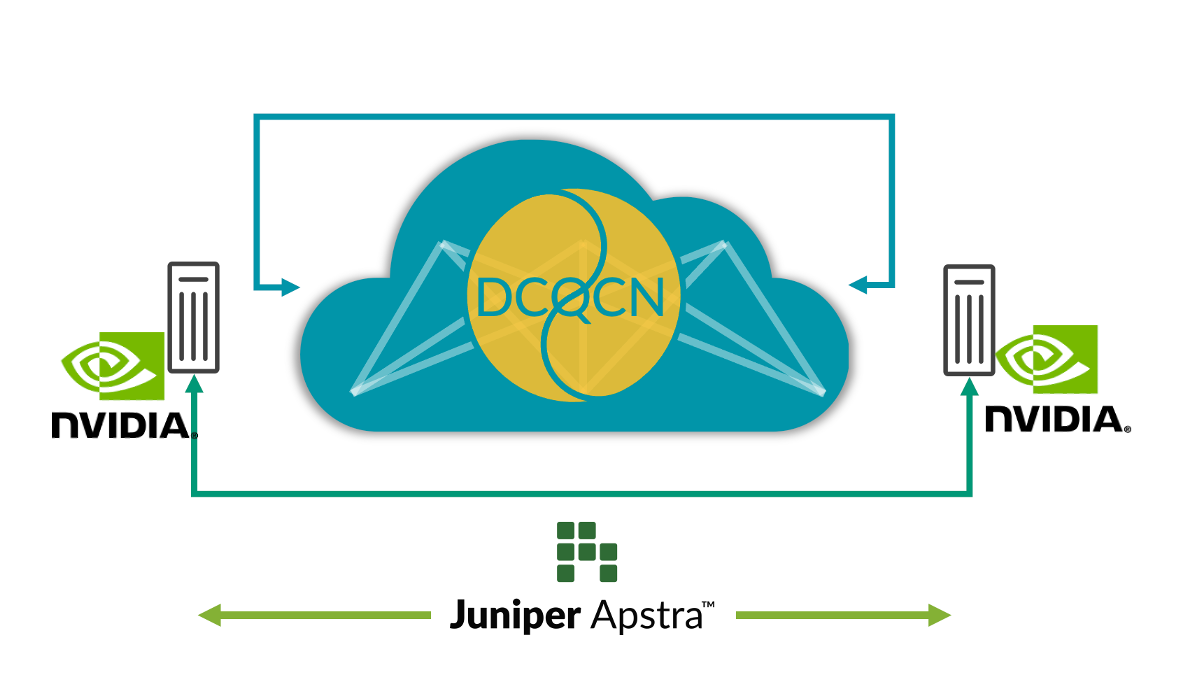
Figura 3: Visibilità E2E dalla rete alle SmartNIC
Per saperne di più, partecipa a “Seize the AI Moment”, il nostro evento online, che si terrà il 23 luglio e che vedrà la partecipazione di un gruppo di clienti Juniper e di esperti riconosciuti del settore che parleranno di ciò che hanno imparato nel mondo in rapido sviluppo dell’infrastruttura dei data center AI.
Dichiarazione d’intenti sui prodotti. Juniper Networks può divulgare informazioni relative allo sviluppo e ai piani per prodotti, funzionalità o miglioramenti futuri, note come dichiarazione d’intenti sui prodotti o piano d’azione (“POR”, Plan of Record ). Questi dettagli si basano sugli sforzi e piani di sviluppo attuali di Juniper. Questi sforzi e piani di sviluppo sono soggetti a modifiche a esclusiva discrezione di Juniper, senza preavviso. Salvo quanto stabilito negli accordi definitivi, Juniper Networks non fornisce alcuna garanzia e non si assume alcuna responsabilità sull’introduzione di prodotti, funzioni o miglioramenti descritti in questo sito web, presentazione, riunione o pubblicazione, né è responsabile per eventuali perdite derivanti dall’affidamento al POR. Le decisioni di acquisto da parte di terze parti non devono basarsi su questo POR e nessun acquisto è subordinato alla fornitura da parte di Juniper Networks di qualsiasi funzione o funzionalità descritta in questo sito web, presentazione, riunione o pubblicazione.


