





















If you are interested in learning the basics of Segment Routing (SR), you have arrived in the right place. Whether you are new to SR or simply looking to learn more about the technology, this blog will provide you insights to help you on your journey by exploring the three key aspects of SR: domain, path and control plane.
Segment Routing Overview
Segment Routing uses a routing technology or technique known as source packet routing. In source packet routing, the source or ingress router specifies the path a packet will take through the network, rather than the packet being routed hop by hop through the network based upon its destination address. However, source packet routing is not a new concept. In fact, source packet routing has existed for over 20 years. As an example, MPLS is one of the most widely adopted forms of source packet routing, which uses labels to direct packets through a network. In an MPLS network, when a packet arrives at an ingress node an MPLS label is prepended to the packet which determines the packet’s path through the network.
While SR and MPLS are similar, in that they are both source-based routing protocols, there are a few differences between them. One of these key differences lies in a primary objective of SR, which is documented in RFC7855, “The SPRING [SR] architecture MUST allow putting the policy state in the packet header and not in the intermediate nodes along the path. Hence, the policy is instantiated in the packet header and does not require any policy state in midpoints and tail-ends.” Unlike MPLS, SR does not require the intermediate routers to maintain path information. This provides a couple of benefits, which we will cover in a subsequent blog, but the primary benefit is that you are able to remove protocols like RSVP and LDP from the network.
Yet, it is important to note that SR can be used with MPLS. In fact, these two protocols will work together, synergistically. RFC7855 also states that, “the SPRING [SR] architecture objective is not to replace existing source routing and traffic-engineering mechanisms, but rather to complement them and address use cases where removal of signaling and path state in the core is a requirement.“
With a basic understanding of what SR is and how it compares to existing source-based routing solutions, let’s look at its components.
Segment Routing Domain
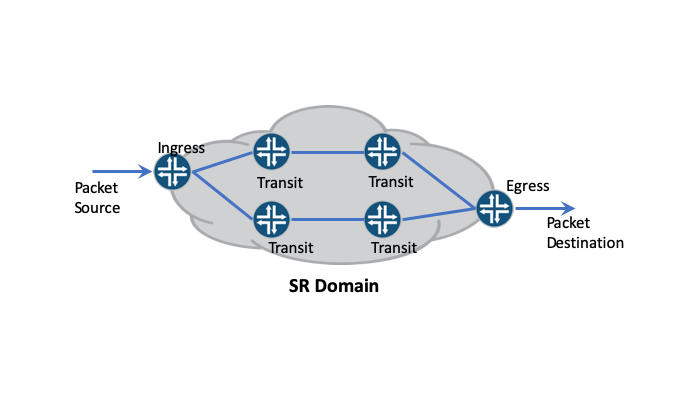
The SR domain is a collection of nodes or network devices that participate in SR protocols. Within an SR domain, a node can execute ingress, transit or egress procedures. Typically, with SR networks, the source and end-point nodes reside outside of the SR domain, while the path between them traverses through the SR domain.
Segment Routing Path
The SR path is an ordered list of network segments that connect an SR ingress node to an SR egress node. However, network segments are not SR path specific, so many SR paths can share a single segment. While an SR path can follow the least cost path from ingress to egress, it can also follow another path for traffic engineering and network service administration purposes. SR paths can be comprised of multiple segment types, which are identified by Segment Identifiers, which we refer to as SIDs. SR segment types include adjacency, prefix, anycast and binding segments. While a path can be comprised of one or more of these segment types, adjacency and prefix segments are the most common types.
Segment Routing Control Plane
The SR control plane provides the “brains” of the operation, creating and managing the SR paths, which is done by a path computation function that resides on the ingress router or by a centralized Path Computation Element (PCE). If a PCE is used, it often resides on a Path Computation Element Controller. The ingress router becomes the Path Computation Client (PCC) and the Path Computation Element Protocol (PCEP) is used to communicate between them.
SR paths can follow the least cost path to the egress node or constraints can force them to follow another path specified by the ingress node. The SR path can be engineered by the PCE to satisfy any number of constraints (e.g., minimum link bandwidth, maximum path latency). While path computation can reside solely on the ingress routers, there are a number of benefits to centralizing this function, which are captured in subsequent blogs that can be found here.
Let’s look at how this works – when a packet arrives at the SR ingress node, the ingress node subjects the packet to policy. The policy includes match conditions and actions. If the packet satisfies match conditions, the SR ingress node assigns the packet to an SR path. The SR ingress does this by encoding the associated segment list in the packet’s SR Header (SRH) or in the case of SR-MPLS, it encodes the segment list in an MPLS label stack and places that in the MPLS label header. It then forwards the packet downstream. Transit nodes process the header, forwarding the packet from the current segment to the next segment. In this way, the packet travels through the SR domain and traverses an SR path to the egress node.
The Benefit
Because the SR ingress node encodes path information in the SR header, transit nodes are not required to maintain information regarding each path that they support. They are only required to process the segment identifiers found in the packet header, forwarding the packet from the current segment to the next segment.
This is the major benefit of SR. Because transit nodes are not required to maintain path information, overhead associated with maintaining that information is eliminated. As a result, routing protocols are simplified, scaling characteristics are improved, and network operations become less problematic.
While encoding path information in the packet and removing it from the transit node introduces some new challenges, the engineering trade-offs are largely positive. These engineering trade-offs will be discussed in subsequent blogs.
Join us on June 10 (US/EMEA) and June 11 (APAC) to discover how network architectural shifts create business value at our Juniper Virtual Summit for Cloud & Service Providers. Register here.


