





















The need for deep-buffer switches in data centers has been a debated topic in the industry for several years. However, are all deep-buffer switches available in the market today created equal?
Where are deep-buffer switches relevant in the data center?
These are some situations where deep buffers switches are relevant in data center environments:
- Big Data applications are inherently bursty. Hundreds of slave nodes processing data in a big data cluster will send bursts of traffic, almost instantaneously, to the master node. These bursts lasting 10s of millisecond can congest the path to the master mode. In a worst-case scenario, a loss of traffic might cause the application to retransmit, thus increasing overall latency experienced by the consumer, while adding more load to an already congested network.
- Storage applications demand packet resiliency and have low tolerance for traffic loss.
- Increasingly, chip sets for data center switches are capable of supporting high logical scale (for example, 2M FIB entries) and advanced routing capabilities (MPLS, IPFIX, NG-MVPN, EVPN and so on). These capabilities enable the positioning of these switches for Data Center Interconnect (DCI) roles, including the possible collapsing of multiple layers in the data center (spine and DCI) for TCO savings. WAN-facing interfaces are expensive and hence an oversubscription exists between data center facing fabric throughput (high bandwidth) and WAN facing throughput (low bandwidth). This impedance creates choke points in the network where packet buffering can smoothen the flow and minimize traffic drops.
- And finally (and this is less than scientific) I have come across so many enterprise data center network operators and architects who have faced application resiliency issues due to shallow buffer systems in their network. When they replace their spines with deep-buffer systems, the problems seem to magically disappear.
Juniper’s deep-buffer spine
Juniper’s solution in the data center for deep-buffer spines and DCI is the QFX10000 series of fixed and modular switches. The Q5 chip powers the first generation of switches in this portfolio (More on Q5 ). Each Q5 chip interfaces with external memory where packet buffering happens. Juniper’s choice for this external memory is a class of 3D memory technology called Hybrid Memory Cube (HMC). This design choice allows the QFX10000 switches to offer uncompromised buffering capability of up to 100 milliseconds per egress port. Alternate deep-buffer systems in the market utilize DDR memory for packet buffering, which has its limitations at high speeds (more on that below).
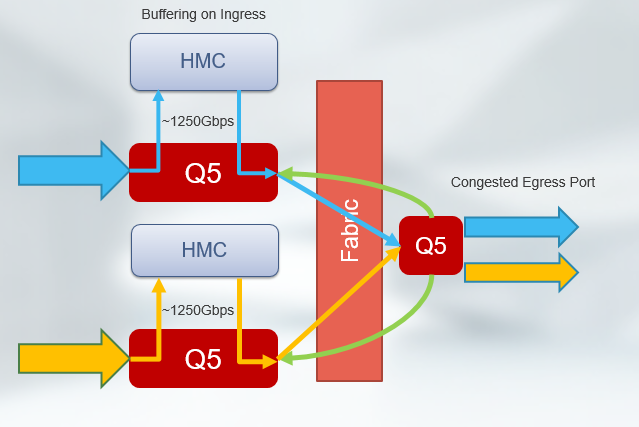
The Q5-HMC complex is depicted below. While each Q5 chip handles 500Gbps worth of throughput, its interface to the HMC memory has a throughput (also called memory bandwidth) of 1.25Tbps.

The QFX10K has a VOQ architecture. This means that when an egress port faces congestion, the ingress chip that is sending traffic to the congested port buffers the traffic flow (see below). All traffic traverses the HMC memory and since the memory bandwidth is 1.25Tbps, this pipe between the Q5 and the HMC has no bottlenecks. Congestion or not, the chip is able to forward at its advertised speed of 500Gbps. The choice of HMC allows the QFX10K to offer guaranteed deep buffering capabilities.
Where competitive deep-buffer promises fall short
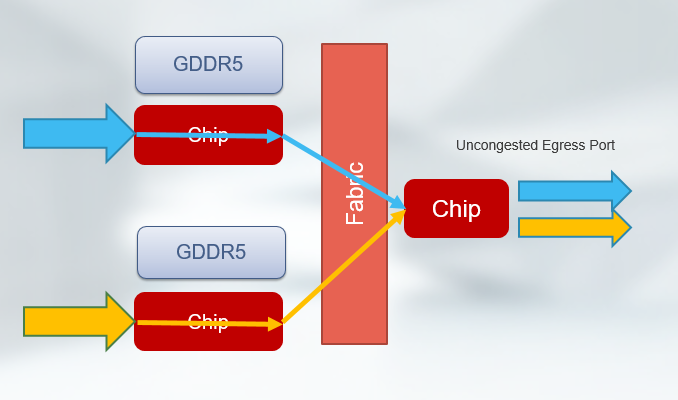
Some competitive systems in the market adopted the use of DDR memory for building switches with similar advertised deep buffering capabilities. As long as there is no congestion on the egress port, everything is great since the traffic does not hit external memory and is processed instead by the small on-chip memory on the chip (See below).
However, in a congestion scenario, traffic traverses the external memory, and DDR memory offers a memory bandwidth of <450G Gbps. Therefore, while the chip advertises a throughput much higher than 500Gbps, effectively the speed of the CPU and memory complex reduces to the speed of the lowest common denominator – which is 450Gbps.
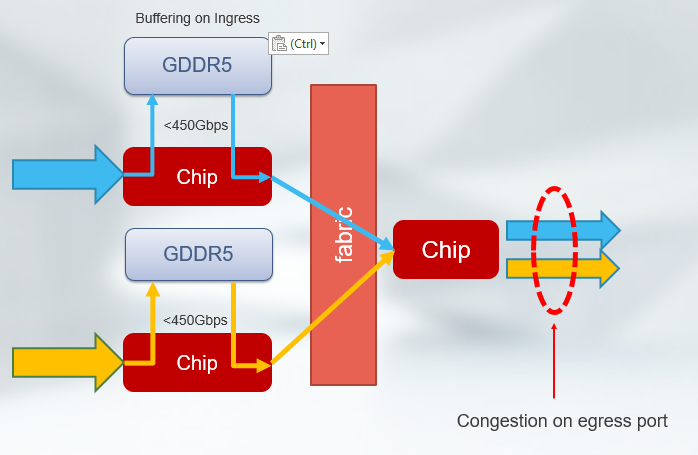
This behavior translates into two effects network operators would see:
- In the presence of congestion, the switch will operate at a speed less than the advertised capability. Presumably, the reason you are deploying a deep-buffer switch is to handle congestion. Ironically, congestion makes the behavior worse reducing the effective throughput of the chip during times when needed the most.
- Bursty traffic of up to 10 milliseconds is not unusual. Most deep-buffer systems advertise the ability to absorb 50 milliseconds worth of bursts per egress port. Our testing has shown that in certain cases, even 2 millisecond bursts with 100 millisecond intervals are not absorbed by these.
Conclusion
The QFX10K series of switches from Juniper can handle congestion scenarios and microbursts without any loss of performance and hence are ideally suited for big data, storage and other applications where resiliency of the traffic flow is critical and applications rely on the network to minimize packet drops.


