





















I think it’s safe to say that my post last week on Network Reliability Engineering made a bit of a splash. This is just the beginning of a long story, and it’s clear that the post kick-started a lot of nuanced conversations we really need to have in our industry.
Being an introductory post, there’s a lot of detail I just couldn’t get into yet, but over the next few weeks and months I hope to spend some time unpacking the nuance behind the concepts I outlined there.
Top of mind for me at the moment is the idea behind the term “Network Reliability Engineering” itself. Why do we need a “new” term in an industry that’s already so buzzword-laden? What’s different about NRE versus, say…DevOps or DevNetOps? How can we get more space on our poster board so we can make our “buzzword bingo” game even bigger? I’d like to address some of that in this post (not that last one, that’s on you).
NRE: What’s In A Name?
Understandably, conversations surrounding new terminology always takes one of two positions. First, there’s the position that we already have established terminology in adjacent disciplines, so we shouldn’t bother having a separate term to “muddy the waters”.
On the other hand, those that are less bleeding edge are looking at pretty much every new buzzword with a (somewhat justified) skeptical eye, and writing them off, assuming it’s not for them. After all, Google is behind the whole SRE thing, and I am nothing like Google, so there must not be anything for me to learn there, right?
The ideal position is somewhere in the middle. While it’s VERY true that we have no business inventing our own way of doing things, there’s also value in having a name that’s inviting for those that would otherwise assume the concepts aren’t intended for them.
This is very similar to the confusion surrounding the term SRE and the seemingly-kind-of-related “DevOps” buzzword. Without a direct mapping of what means what, it can be easy to confuse the terms. Fortunately, some SREs at Google recently released a fantastic video explaining the difference between the “SRE” and “DevOps” terms:
In short, you can think of “DevOps” as a core set of principles to follow, and an SRE is a specific individual or job role that upholds those principles. In the very same way, an NRE is someone that implements the core principles of DevOps, in a network engineering context:
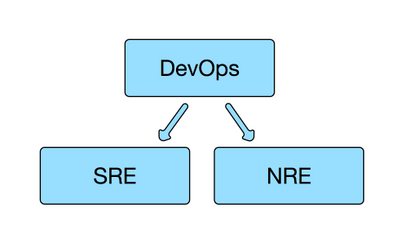 So, NRE isn’t just doing our own thing in isolation – it’s actually an acknowledgement that we have already been doing our own thing and need to stop. We’ve insisted on managing networks differently from the rest of infrastructure because “we’re special”. Now – there’s no denying that there are clear differences between an SRE and an NRE, just like there are differences between a sysadmin and a traditional network engineer. However, the core principles should be exactly the same.
So, NRE isn’t just doing our own thing in isolation – it’s actually an acknowledgement that we have already been doing our own thing and need to stop. We’ve insisted on managing networks differently from the rest of infrastructure because “we’re special”. Now – there’s no denying that there are clear differences between an SRE and an NRE, just like there are differences between a sysadmin and a traditional network engineer. However, the core principles should be exactly the same.
So, Network Reliability Engineering is a vessel for making network operations look much more like how the rest of the infrastructure is managed. This is done by aligning with the same core principles. In keeping with the metaphor established in the video above, NRE uses the same abstract interface, but simply with a different concrete class.
So, how does NRE implement DevOps? I built a table below that lists the five DevOps principles outlined in the video above as well as the way that SRE implements each principle. I added a third column that explains how NRE also implements each principle:
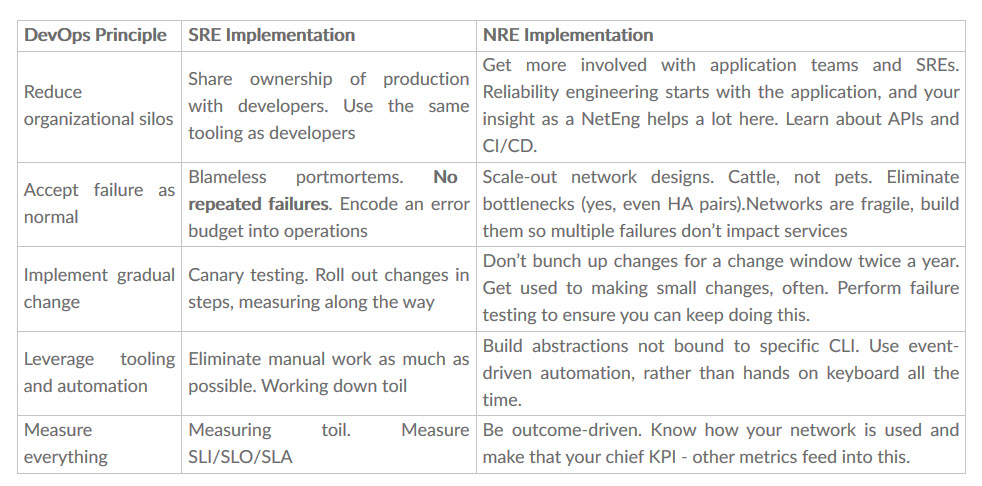
You’ll note that the NRE column is slightly different from the SRE column, but is identically aligned with the same core DevOps principles. So, in summary, NRE is inherently different for a few reasons:
- Our customers are not the same. Often, an SRE is actually a customer of an NRE. We also have a slightly different relationship with our vendors, though this is changing.
- The nature of the technology is different. Many “traditional” SREs deal only with end-nodes like servers (obviously not all do, some are actually NREs with an SRE title), whereas NREs deal with network devices. Blast radius, tools, technologies all tend to be a little different, even in “evolved” automated network operations.
- NRE is purpose-built for network engineers. It’s an augmentation – not abandonment – of existing network engineering skills.
NRE is also NOT different in a few ways:
- NRE is still about reducing toil
- NRE is still outcome-driven
- NRE is still all about planning and designing for failure
NRE and Silos
Another concern with new terminology is that it will be used as a rallying cry to put up those silos and walls we’ve worked for years to tear down:

Indeed, putting up walls is not the goal, and in all we do, we should strive to bring these walls down. If there’s “one core DevOps principle”, I’d say this one is it. So if we’re doing something that puts up walls, we’re on the wrong path.
I alluded to the term “outcome-driven” in the table above, and you’ll be hearing a lot about being outcome-driven in the weeks to come, and indeed from nearly all existing SRE material. But what does this mean?
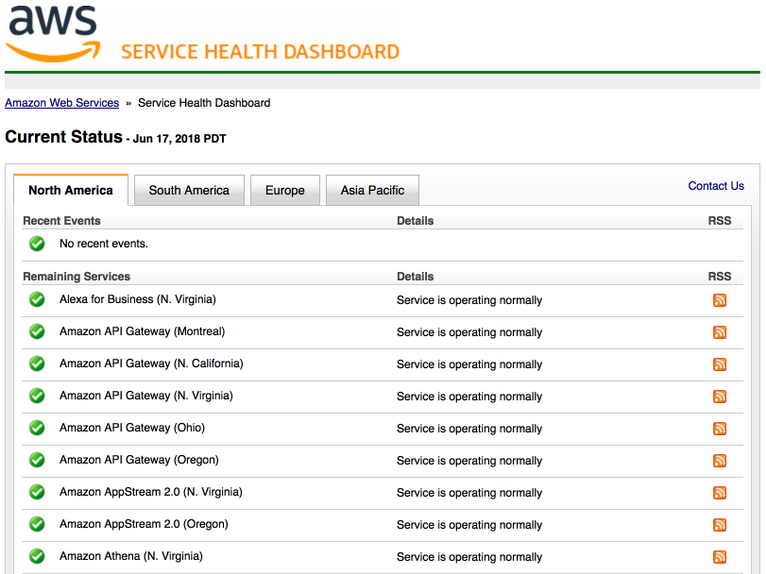
One of my favorite (slightly antagonistic) examples I like to bring up on this topic is the AWS health dashboard. As a customer of AWS, no matter which of their services you use, you can see here, at-a glance, the health of each service in each region:
I can even subscribe via RSS feed to each service’s status. The reason this is helpful is that the health dashboard is totally aligned with the outcomes I’m expecting from AWS. I can go straight to the service I’m using and see if it’s available in my region.
In stark contrast, here’s a mocked-up example of what we as network engineers tend to provide to our customers:
Great. “switch001” is up. Thanks, I guess. Or, put another way, who gives a crap?!? I am a network guy and even I couldn’t care less about which switches are up or down within AWS’s infrastructure. Why? Because network devices aren’t what I’m consuming, its the services that ride on top of them. No doubt that those network devices are crucial for those services, but it’s the services that I care about above all.
Let me be clear – no one is in a better position to make this mapping between “device health” and “service health” than a network engineer.
It is for this reason that NRE is about tearing down silos, not building them up. The way we’re doing things today, with a “device-centric” external interface is very much a siloed approach. It doesn’t matter if you’re using Ansible or Puppet to do “network automation”; if the network is presented to its customers like that second “fake” AWS dashboard, the needle hasn’t moved very far, and we still have silos. On the contrary, an outcome or service-driven approach to building networks means you are putting the customer and their use cases first, and all decisions stem from that. In order to make that happen, you have to be more involved with your customers and adjacent technical disciplines, including application developers and sysadmins.
Onward!
Hopefully I’ve been able to demystify and disambiguate some of the ideas behind Network Reliability Engineering, and more tangibly inspire you to consider that these changes are within reach for all of us – not just for our employer’s benefit, but also our own.
The core DevOps principles that power NRE, as well as the specific skills that implement them, are already in high demand, and those that embark on this journey are sure to find a more interesting and rewarding career path. Stay tuned for the next post in this series as we go further down the rabbit hole.


