





















Training AI models is a special challenge. Developing foundational large language models (LLMs), like Llama 3.1 and GPT 4.0, requires massive budgets and resources reserved only for a handful of the largest companies in the world. These LLMs have billions to trillions of parameters that require complex data center fabric tuning to train within a reasonable job completion time. For example, GPT 4.0 uses 1.76 trillion parameters!
To put those numbers into perspective, imagine each parameter as a playing card. A deck of 52 playing cards is roughly 0.75 inches thick. A stack of a million cards would be taller than the Empire State Building, a stack of a billion would be 228 miles high into the Earth’s thermosphere, and a stack of a trillion would stretch over 227,000 miles, roughly the distance to the moon.
Make the most of your AI investments
For many enterprises, investing in AI requires a new approach: refining these foundational LLMs with their own data to solve specific business problems or offer deeper customer engagements. But as AI adoption blankets the playing field, enterprises want new ways to optimize their AI investments for increased data privacy and service differentiation.
For most, this means shifting some of their AI workloads on-premises into private data centers. The ongoing “public vs. private cloud” data center debate applies to AI data centers as well. Many enterprises are intimidated by the newness of building AI infrastructure. Challenges do exist, but they’re not insurmountable. Existing data center knowledge is applicable. You just need a little help, and Juniper can guide you.
In this blog series, we look at the different considerations for enterprises investing in AI and how different approaches are driven by what Juniper calls the ABCs of AI data centers: Applications, Build vs. Buy, and Cost.
But first, let’s look at why AI infrastructure needs to be so specialized.
Understanding LLMs and neural networks
To better understand infrastructure options, it helps to understand some fundamentals of AI architectures and the basic categories for AI development, delivery, training, and inferencing.
Inferencing servers are hosted on internet-connected front-end data centers where users and devices can query a fully-trained AI application (e.g., Llama 3). Using TCP, inferencing queries and traffic patterns mirror that of other cloud-hosted workloads. Performed in real time, inferencing servers can use common computer processing units (CPUs) or the same Graphic Processing Units (GPUs) used in training to provide the fastest response with the lowest latency, commonly measured through metrics such as time-to-first-token and time-to-incremental-token. Essentially, this is how quickly the LLM can respond to queries and, at scale, may require significant investment and expertise to ensure consistent performance.
Training, on the other hand, has unique processing challenges that require special data center architectures. Training is performed in back-end data centers where LLMs and training datasets are isolated from the ‘rogue’ internet. These data centers are designed with high-capacity, high-performance GPU compute and storage platforms with specialized rail-optimized fabrics using 400Gbps and 800Gbps networking interconnects. Due to large “elephant” flows and extensive GPU-to-GPU communication, these networks must be optimized to handle the capacity, traffic patterns, and traffic management demands of continuous training cycles that can take months to complete.
The time it takes to complete training is dependent on the complexity of the LLM, the layers within the neural network to train the LLM, the number of parameters that must be tuned to improve accuracy, and the design of the data center infrastructure. But what are neural networks and what are the parameters that refine LLM results?
Neural networks 101
A neural network is a computing architecture that is designed to mimic the computational model of the human brain. They are implemented in a set of progressive functional layers with an input layer to ingest data, an output layer to present results, and hidden layers in the middle that process the raw data inputs into usable information. The output of one layer becomes the input for another layer so that queries can be systematically broken apart, analyzed, and processed across sets of neural nodes, or mathematical functions, at each layer until results are rendered.
For example, the image below represents an LLM being trained on a neural network to recognize the handwritten digits of the first four even numbers. This neural network has two hidden layers, one to process shapes and the other to recognize patterns. Datasets of handwritten numbers are chopped up into smaller blocks and fed into the model where curves and lines are functionally processed at the first layer before sending to the second layer to identify patterns in the data that might indicate the number being analyzed.
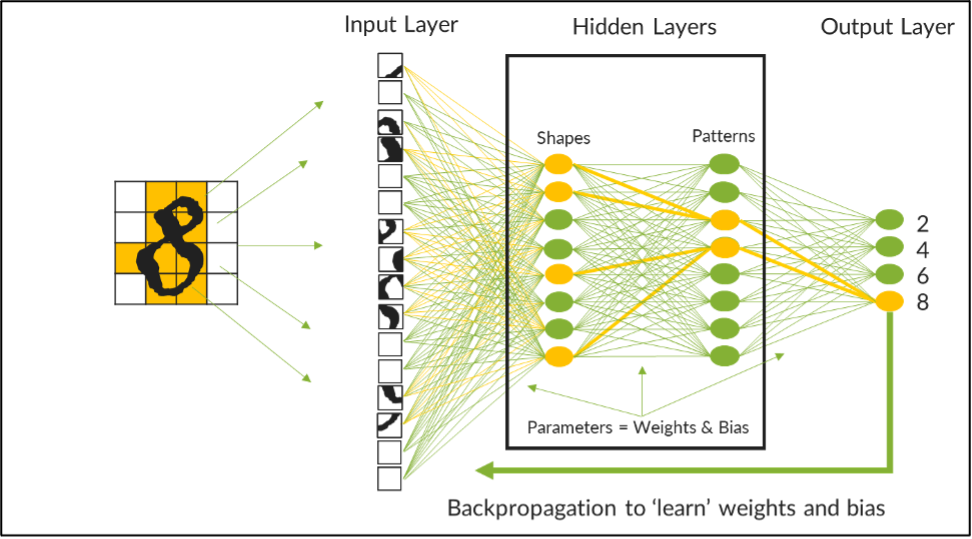
Tuning parameters for optimal LLM accuracy
Neural nodes within each layer have a mesh of neural network connections that allow AI scientists to apply weights to each connection. Each weight is a numeric value that indicates the strength of the association to a given connection. For example, a curve in an upper quadrant of the data would have a higher weight for a 2 or an 8 while a line in the same quadrant would have a lower weight for the same. When looking at patterns, a set of vertical and straight lines may have a strong connection and higher weight for a 4 while lines and curves together would have a stronger connection and weight for a 2, 6, or 8.
At the start of training, the results of the model will be impossibly inaccurate. However, with each training run, the weights of these neural connections can be adjusted or “tuned” to progressively increase accuracy. To further distinguish strong versus weak connections, a numeric bias is applied to each connection to amplify strong connections and govern negative connections. Together, weights and biases represent the parameters that must be tuned to refine the accuracy of an LLM.
In this modest example, there are 242 parameters that must be repeatedly tuned before the model can identify each number with a high degree of accuracy. When dealing with billions or trillions of parameters, algorithms for backpropagation are used to automate the process. Still, training is a very long process that can be delayed or interrupted by processing latencies that can occur in the underlying physical network of the data center. Referred to as tail latency, this can compound to add significant time and cost to the training process unless the data center network has been properly designed.
In the next blog, we’ll talk about how enterprises can leverage these foundational LLMs to deploy their own custom AI applications delivered from private data centers.
Want to hear how other organizations are building the infrastructure to tackle these challenges? Check out our virtual event Seize the AI Moment for insights from AMD, Intel, Meta, PayPal, and many more.


