





















您是否感到无所适从?不妨浏览一些新闻稿,了解新的芯片解决方案!要论最能让您对未来感到兴奋的技术,那一定非全新特定于应用的集成电路 (ASIC) 莫属。但如果快速浏览一下 Cisco、Nokia 和其他公司最近的公告,您会发现有一个词从未出现过:权衡。这令人感到遗憾,因为任何好的芯片设计都会优化其架构,为客户实现特定的成果——有时甚至会以牺牲其他成果为代价。如果供应商对芯片设计中的优化避而不谈,那么他们一定是有所保留。
在瞻博网络,网络的某一部分不会为了改进另一部分而受到损害。这就是为什么瞻博网络多年来一直采用多芯片战略,提供采用不同芯片组的平台,针对网络中的不同职能进行优化。今天,我们将继续实施这一战略,发布最新一代的瞻博网络 Trio 和 Express ASIC。随着网络变得越来越复杂,坚守一个十多年来成功服务客户的理念是个不错的选择:唯有选择合适的工具,才能让网络发挥出最佳效果。
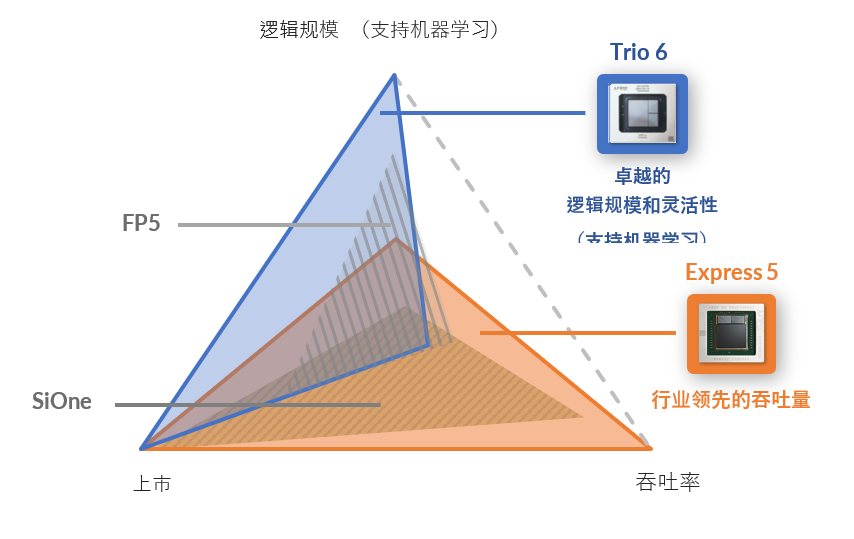
特别是对于网络芯片,任何设计都需要在逻辑规模与吞吐量之间求取平衡。想要在多个同时进行的维度上提高逻辑规模,就需要增加内存,但要增加内存以支持每秒几十 Tb 的吞吐量,还需要进行优化。换言之:设计一种高度灵活的 ASIC,使其为各种复杂的任务提供多功能性与逻辑规模,或者设计一种能通过以带宽为中心的角色提供惊人吞吐量的 ASIC。但在单一设计中同时优化两者是不可能实现的。
以多样化推动专业化
过去二十年来,随着网络的发展,支持的数字服务更加多样化,要求也愈加严苛,运营商开始不断寻求专门的芯片来应对特定的职能。从最高级别的角度来说,用于优化网络 ASIC 的两种能力之一就是找到正确的工具:
- 灵活的逻辑规模:在提供消费宽带 (BNG) 和商用虚拟专用网络 (VPN) 功能用例的高动态多服务边缘节点,最重要的要求就是高逻辑规模和灵活性。在网络边缘,平台需要支持各项服务产品和用例的复杂功能,如非常庞大的路由转发表、灵活的隧道封装、丰富的服务质量 (QoS)、防火墙安全过滤功能,以及在同一高级别的逻辑规模上为每项服务附加流量管理计数器的能力等。相应地,这些需求又会推动巨大的内存需求,以便针对边缘职能快速执行大规模、大范围的复杂数据库查询。随着越来越多的运营商转向使用机器学习 (ML) 来帮助更快速地关联和识别复杂的问题,以期改善网络正常运行时间并提供更好的客户体验,同样的需求又会周而复始地出现。为了在多服务边缘的本地机器学习处理方面拥有出色表现,我们需要非常多样的功能。
- 高吞吐量:在网络的其他部分(比如用于传输聚合和核心的转发节点),脚本会被倒转过来。核心节点不必托管同样的网络功能,因为它们并不直接支持逻辑订阅者或 VPN。但它们需要处理大量流量,以满足不断增长的吞吐量需求。因此,我们需要对核心节点进行优化,以提高带宽吞吐量和转发性能,并为吞吐量、过滤、遥测和采样功能等已知的操作提供所需的管道和内存特性。
归根结底,芯片设计是一个多变量方程,其中逻辑规模和吞吐量是截然相反的变量。在给定的芯片尺寸和功耗预算内,您可以针对最高带宽吞吐量或最高逻辑规模进行优化。但必须遵循“此消彼长”的规律。
在这种情况下,很难理解为什么一些供应商不愿意谈论优化。我们需要具备优化网络芯片的能力,这样就可以使用已针对不同带宽点和服务规模点之特定领域需求进行了优化的平台。只有在网络的不同部分对不同的职能进行优化,才能实现体验至上的网络。
最新一代的瞻博网络芯片组为客户提供了选择权
多年来,为客户提供最适合的工具一直是瞻博网络的芯片战略——为网络中的不同职能提供 ASIC 选择。瞻博网络在 2009 年为瞻博网络 MX 系列路由器发布第一款 Trio 芯片组后便制定了这项决策。作为业界第一款完全可编程的网络 ASIC,Trio 为多服务边缘提供了突破性的解决方案。但很快我们就发现,一种类型的芯片无法满足客户需要解决的所有不同用例。因此,在 2012 年,瞻博网络为 PTX 系列平台推出了 Express 系列 ASIC,这款芯片专门为网络核心和对等网络用例中的高带宽应用而开发。
至此网络和 ASIC 不断发展,但这些早期的经验教训仍然是正确的:选择需要多多益善。有了针对不同任务进行优化的 ASIC,网络运行变得更加顺畅。现在,我们又将这些经验运用到最新几代的瞻博网络芯片组。
- 瞻博网络 Trio 6 – 专为探索未知而打造:借助这款新芯片组,瞻博网络正在推出冠绝业界的多服务边缘解决方案产品组合,以及唯一一款从头开始优化多业务用例的网络芯片组。
- 用于 MX 系列路由器的第 6 代 Trio 芯片为最为复杂多变的边缘服务节点提供了卓绝的逻辑规模和可编程性
- 这套解决方案为 MX 10000 系列提供了6T 线卡
- 支持机器学习的 Trio-6 芯片提供对 IPSec 的本地支持,以及在本地线速下的集成 MACsec
- Trio 6 还采用了 7 纳米制造工艺,与前几代芯片组相比,功率效率提高了 70%
- 这是一款无可比拟的先进芯片,专为探索未知而打造,能够灵活支持当今和未来的各种用例
- 而且,与最近发布的几款在几个季度内都不会投入市场的 ASIC 不同,Trio 6 已经开始现货供应
- 瞻博网络 Express 5:瞻博网络 Express 5 可以在单一封装中提供业界最高的8T 无阻塞吞吐量——相比之下,Cisco 最近发布的 P100 芯片只能提供 19.2Tbps 的吞吐量,比瞻博网络的新款 Express 5 芯片低 33%——落后几年可想而知。Express 5 适用于 PTX10K 系列平台的所有高吞吐量用例,性能上毫不妥协。Express 5 芯片于 2021 年推出,将在不久之后出货。
- Express 5 具有固定的外形尺寸,其8T 的吞吐量将提供低功耗的 36 * 800G 端口基数
- 采用 7 纳米技术打造,功率效率比以前的芯片组高出 45%
- 如最新的 PTX EANTC 测试所示,其所有 KPI 均遥遥领先
总之,这些新的 ASIC 可为平台部署提供所需的灵活性,让这些平台能够针对网络不同部分的严苛逻辑规模或吞吐量要求进行优化。而竞争者们只能望洋兴叹。想要面面俱到,结果往往杂而不精。
在瞻博网络,我们主要在灵活性和选择性方面进行了投资,这让我们能够为客户提供最适合的工具。瞻博网络与其他供应商的不同之处在于,我们拒绝“一体适用”的模式。
“随着网络服务需求的增长和多样化,网络平台设计和网络架构也在不断变化。没有一种芯片组能够始终满足所有需求——从灵活性和可扩展性到吞吐量和性能——这就是为什么瞻博网络计划对芯片进行优化和专业化处理,以满足网络中特定位置的特定需求,这是一种以客户为中心的理想战略。瞻博网络一致的芯片架构使运营商的投资能够面向未来,这为运营商的网络现代化带来了更大的价值。” ——Ray Mota,ACG Research
面向未来
开发新芯片需要巨大的投资,通常需要三到五年的研发时间,产品才能上市。因此,供应商试图降低这些成本并不令人惊讶。在单一芯片架构上进行标准化处理可以帮助节省成本,但这也意味着客户将被迫作出妥协。可以尝试针对最佳情况下的吞吐量进行优化,但使用 IMIX 流量将无法通过 RFC 2544 测试,如 Cisco 的 8201。(EANTC 结果见此处)。或许可以像 Nokia 一样,试图让一个芯片组执掌多个职能,并以吞吐量为代价推进逻辑规模(结果落后竞争对手数年之久)。Nokia 最近宣布,他们终于能在 2022 年提供 14.4T/插槽的吞吐量。相比之下,瞻博网络在过去三年里一直在推出能够提供这种性能的产品。在 Nokia 宣布他们的第一张 14.4T 卡之前,我们已使用 14.4T 解决方案向 200 多家客户交付了数万个 400G 端口。而瞻博网络新推出的 Express 5 芯片的吞吐量是 2019 年的两倍。
 或者,直接制定一个芯片战略,围绕什么是对客户最有利的,而不是什么对利润最有利。在瞻博网络,我们主要进行选择性和优化方面的投资,因此不存在任何妥协。瞻博网络将为您提供具备以下特色的芯片:
或者,直接制定一个芯片战略,围绕什么是对客户最有利的,而不是什么对利润最有利。在瞻博网络,我们主要进行选择性和优化方面的投资,因此不存在任何妥协。瞻博网络将为您提供具备以下特色的芯片:
- 采用一致的架构:客户已经采用了可用数年之久的优化型芯片架构所打造的产品系列,但供应商却突然改变了方向——没有什么比这种情况更具颠覆性或代价更高的了。从多代芯片组的性能和可扩展性的持续改进中受益,同时保持一致的行为和操作,这才是应有的成果。这也是瞻博网络在过去 13 年里努力的方向。我们的创新周期从一代产品顺利过渡到下一代产品,客户无需更换平台或重新配置和培训员工,就可以升级到最新的线卡。
- 提供更环保的运维:同样地,供应商不能只是为了减少碳足迹,就要对网络进行全面改造。对于使用瞻博网络 ASIC 的客户,自瞻博网络第一代 芯片组以来,其功率效率已提高了 95%。
提供选择性和灵活性,并针对不同工作提供专用芯片,这些是指导瞻博网络芯片战略的原则,也是实现体验至上网络的秘诀。至于竞争对手,他们不想谈论他们为优化芯片所做的选择是有原因的:这也没什么可说的。


