If you’ve ever worked in network operations, you undoubtedly have a few crazy stories about network outages and the unusual hours you had to work to resolve them. Outages never seem to happen at 10AM on Monday when everyone is at their desk, freshly loaded with coffee. No, the network Gods seem intent on things failing in the middle of the night or when traffic is close to its peak. And if the failure was during working hours, undoubtedly you’ll have to do some sort of remediation at unpleasant times, without the benefit of having the entire team available to help.
If you’ve ever worked in network operations, you undoubtedly have a few crazy stories about network outages and the unusual hours you had to work to resolve them. Outages never seem to happen at 10AM on Monday when everyone is at their desk, freshly loaded with coffee. No, the network Gods seem intent on things failing in the middle of the night or when traffic is close to its peak. And if the failure was during working hours, undoubtedly you’ll have to do some sort of remediation at unpleasant times, without the benefit of having the entire team available to help.
Why has this become the standard process for dealing with issues? Shouldn’t there be some intelligent software that can automate workflows across an entire network regardless of what vendor hardware is being used? (Spoiler Alert: A “Software First” approach will help solve many of these issues).
No Shortage of Potential Problems
The number of potential problems in a network is unlimited. Devices misbehave or fail outright, optics fail regularly, copper and fiber cables become crimped or even cut, security vulnerabilities affecting multiple devices OS are routine. As owners and caretakers of these environments, we are responsible for designing and operating the network to avoid the most common issues, but we can always expect some sort of issue to appear.
Hardware failures will always exist. We can design redundant hardware and topologies, but when things break, how can we easily replace the equipment without causing further degradation to services?
Software bugs and issues don’t always appear immediately, sometimes there are conditions that set them off, sometimes the increased load drives them to the surface. Occasionally we discover them through notifications from the vendor, typically in the form of a security notice or PSIRT.
Probably worse than outright failures are “gray failures” which add uncertainty to our networks. A device that is dropping a large amount of packets still needs to be replaced, but until the operator has been able to perform this work, real application traffic will continue to be forwarded.
Replacement Challenges
When a device has to be replaced but is still participating in the routing and switching for the fabric, several steps need to be taken to ensure that traffic is gracefully drained. For example, we don’t want to simply shut down the BGP routing process, as this would impact existing traffic flows. We also don’t want to modify the L2 switching plane as this could prove disastrous to the rest of the network. We want a consistent and well-tested routine for placing devices into maintenance mode, with the increased level of trust in this routine we can perform corrective actions during more potential change windows.
Operator Quality of Life
Most network operators are used to the fact that the business is rarely tolerant of changes in the middle of the day. In fact, as the network provides the lifeblood for all of IT, most businesses do not permit changes outside of very small maintenance windows, which are typically early morning on the weekends. Who wants to go into their datacenter at 4AM on Sunday morning? We need a tool that works across different platforms and vendors to reliably drain a device of application traffic and place it into a quarantined state while we repair it.
Introducing AOS® Maintenance Mode
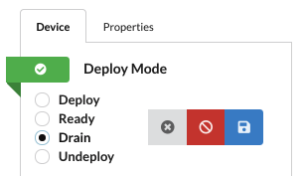 Apstra AOS was built by network engineers, for network engineers. As a result, it includes tools and workflows specifically designed to address the challenges of running a modern data center. AOS supports a complete workflow for taking fabric devices out of service while minimizing impact to active flows. In addition, these workflows are vendor-agnostic, so the same process will occur on different vendor devices even if the command syntax and workflow differs. Lastly, and probably most importantly, by placing a device into Maintenance Mode, we update the overall intent for the network, so monitoring and service expectations are automatically adjusted. No more false positives or the famous “sea of red” in our dashboards.
Apstra AOS was built by network engineers, for network engineers. As a result, it includes tools and workflows specifically designed to address the challenges of running a modern data center. AOS supports a complete workflow for taking fabric devices out of service while minimizing impact to active flows. In addition, these workflows are vendor-agnostic, so the same process will occur on different vendor devices even if the command syntax and workflow differs. Lastly, and probably most importantly, by placing a device into Maintenance Mode, we update the overall intent for the network, so monitoring and service expectations are automatically adjusted. No more false positives or the famous “sea of red” in our dashboards.
AOS enables Maintenance Mode by making small changes to route filters within the BGP process. This causes packets to be routed onto alternate paths according to the ECMP load balancing algorithm. Also, AOS can shutdown server facing ports to force traffic onto the MLAG peer. These combined changes result in one or less lost packets within our application flows, which are easily recovered by TCP or upper-layer protocols. This change occurs in seconds, and the device can be removed from the network for corrective actions.
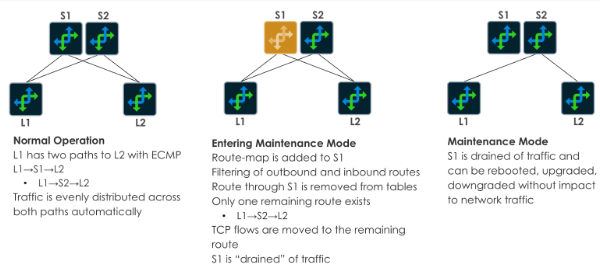
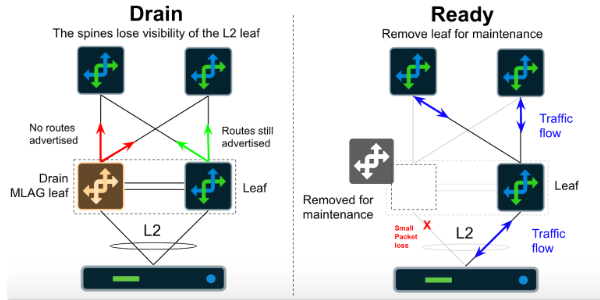
AOS also provides advanced monitoring of drained devices with prebuilt Intent-Based Analytics probes. These probes run within the network all the time. When a device enters maintenance mode, an anomaly is issued if the device has more than a standard level of traffic flowing through the fabric ports. This ensures that we do not modify or power off devices that have not been fully drained. The operator can select the exact traffic level they wish to alert on.
Once the device has entered Maintenance Mode, we can perform other automated actions. In AOS this typically involves moving a device into the Ready state. The Ready state shuts down all L2 and L3 features (L3 routed mode for all interfaces, no neighbor adjacencies, LLDP only).
Once a device is in the Ready state we can simply turn it off and remove it from the rack. A replacement device can be the same vendor hardware or even a different vendor or form factor, freeing us up from finding the exact model previously used. In fact, you can use this method to gradually replace existing switches or even a vendor completely, as AOS automatically renders a configuration for each vendor type without the operator having to do anything aside from selecting the new vendor type from a dropdown box. So we have complete freedom to insert new hardware and ensure that it behaves exactly as the previous device did.
Finally, this process is perfect for performing NOS upgrades.
Read Part 2 of this series on how AOS automates and validates NOS upgrades across an entire IP fabric with a few simple clicks in the UI.