





















When a fault occurs in a network, it’s important to minimize the period of time that production traffic is affected in order to avoid disruption to customers. If a fault is clear-cut, such as a link or node completely failing, then mechanisms such as fast-reroute ensure that traffic is quickly diverted away from the point of failure. However, sometimes grey failures can occur. A network element exhibiting a grey failure is neither completely healthy nor completely failed; it’s somewhere in between. Such failures are particularly insidious because the fault might go undetected by IS-IS or OSPF or Bidirectional Forwarding Detection (BFD), yet may be significant enough to disrupt some of the traffic passing through. Grey failures give operational headaches to network operators, because they are more subtle than a complete failure and might only affect a proportion of the traffic passing through the faulty network element. This makes their very existence and location more difficult to detect, so the disruption time to customers’ traffic can be quite prolonged. When a grey failure occurs, the disruption time is made up of three components:
(i) The time it takes to realize that there is a problem – sometimes, customers are the first to notice that some of their applications are not working properly, before the network operator identifies a fault. The operator only realizes once customers have reported the problem to them.
(ii) The time it takes to pinpoint the location of the fault – operators say that often, it’s like looking for a needle in a haystack.
(iii) The time it takes to remediate – either by fixing the problem immediately or by diverting traffic from the faulty network element.
Juniper Networks’ Paragon™ Automation suite provides a self-healing mechanism that fully automates the process outlined above, greatly reducing the time window during which traffic is disrupted. This is achieved by a combination of Paragon Insights and Paragon Pathfinder. Paragon Insights monitors the health of network elements by analyzing telemetry data streamed to it from the network nodes, enabling detection of a variety of faults or the threat of an incipient fault. It could be a problem with a link, such as accumulating error counts that could indicate that the link will go down before too long. Or it could be a problem with a node, such as excessive CPU utilization or memory consumption. Let’s see how the self-healing process works:
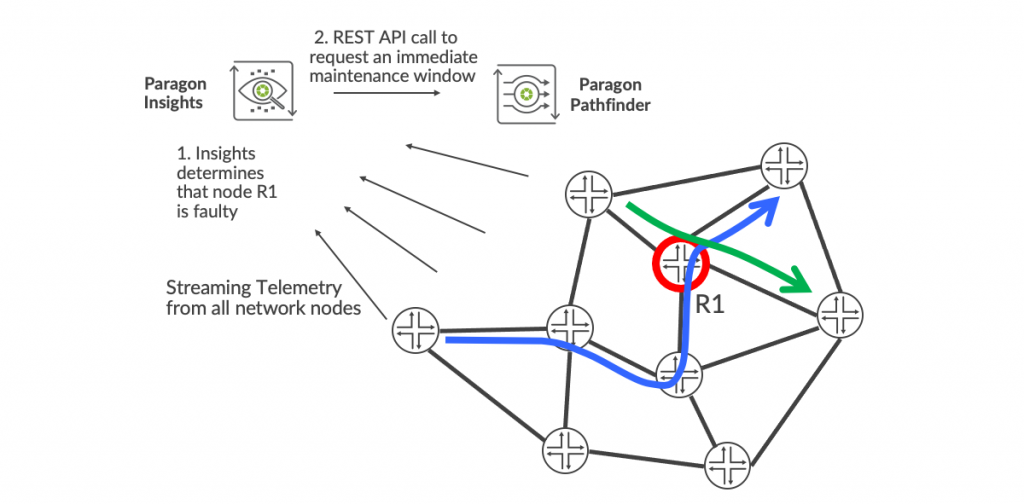
- Paragon Insights determines that there is a fault with a network element, node R1 in the example below.
- Paragon Insights sends a REST API call to Paragon Pathfinder in order to request immediate maintenance on node R1.
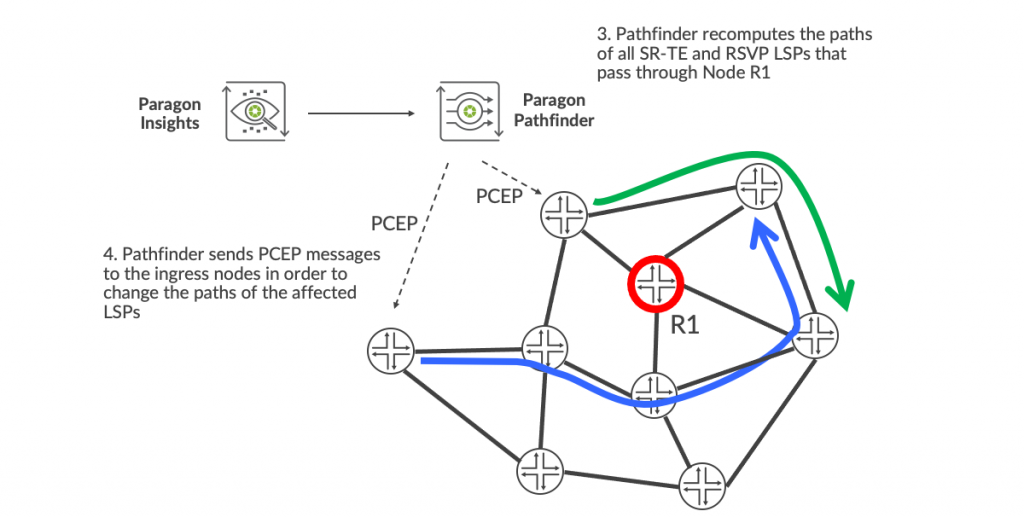
- Paragon Pathfinder prepares for the maintenance by recomputing the paths of all the SR-TE and RSVP LSPs that are passing through the node R1 so that they avoid the node.
- Pathfinder then sends Path Computation Element Protocol (PCEP) messages to the ingress routers of the LSPs so that they move them to the new paths that Paragon Pathfinder has computed. Node R1 is now in maintenance mode – it has been drained of traffic. By default, Paragon Insights requests a maintenance duration of one hour, but ceases the maintenance if the fault is observed to go away. This behavior can be modified by the operator according to their preference.
What happens next depends on the nature of the fault. For some faults, Paragon Insights can be programmed to take remedial action, for example, restarting a software process or resetting a device. In other cases, manual processes may be involved, such as swapping out some hardware. Either way, these procedures can take place without any further disruption to customers’ traffic, as it’s no longer passing through the faulty network element.
But what if diverting the traffic makes matters worse in the network? What if diverting the traffic causes congestion elsewhere because with the node out of service, there is insufficient network capacity? Some may think this might cause more disruption to traffic than the original fault. To address this, in a refinement to the self-healing process, Paragon Insights, having detected the fault, sends an API call to Paragon Pathfinder asking it to perform a simulation. Traditionally, network simulation involves a human operator interacting with a simulation tool via a graphical user interface. Nowadays, such simulations can be API-driven and automated. In the simulation, Paragon Pathfinder imagines rerouting the traffic to avoid the faulty network element to ascertain whether is feasible for the network to carry all of the traffic in the absence of the faulty network element. If Paragon Pathfinder replies to Insights that it is indeed feasible, then Paragon Insights goes ahead and requests Paragon Pathfinder to initiate the maintenance.
The whole process outlined above occurs automatically, without any human intervention and demonstrates how components of the Paragon Automation suite can interact to perform sophisticated self-healing tasks in a fully automated manner. As such, it’s a key stepping stone toward the Self-Driving Network™.


