





















Classical device-centric assurance solutions help network operators keep pace with the volumes of monitoring data supplied by network infrastructure. These solutions identify network device failures and faults so that operators can react quickly to mitigate network outages. However, these solutions are falling short because silent failures caused by errors in network configuration often go undetected, which leads to performance degradations that render end-user applications unavailable and customer dissatisfaction, among other issues.
Independent analyst research shows that customer satisfaction is continuing to be a prevalent issue across the industry and a recent Juniper Networks survey of 200 US enterprises found that more than 60% of network problems are not discovered by network operations. Rather, these problems are often caught by end users or even worse – not at all. This situation was found to result in multi-million dollar losses per year in reduced employee productivity across enterprises and customer churn for service providers.
Today’s network operators are struggling to achieve service quality in the 5G and cloud era where applications demand that strict service level objectives be met in order to maintain a high quality of experience. Whether a network slice or a SD-WAN service, the operational expectations for real-time quality guarantees are quickly becoming mandatory. Communication Service Providers (CSPs) are striving to differentiate through exceptional service quality and customer experience, leaving no room for network issues.
Service Level Agreements (SLAs) Are More Critical to Profitability Than Ever
With customer retention hinging on quality, maintaining SLAs are key to profitability. Traditional performance management tools and their minute-based intervals are no longer sufficient when every millisecond – and even microsecond of latency – counts. Modern business-critical SLAs define extremely low loss, latency, jitter and require guaranteed bandwidth. Performance monitoring is also needed at a sub-second interval rate. Based on the type of application used, modern solutions also differentiate expectations per each individual service, slice and end-user (i.e. a unique SLA guarantee must be met across the network where the priority may be placed on several different metrics, such as availability, jitter, loss, latency, Mean Opinion Score [MOS], bandwidth or a quality of service [QoS] profile).
SLAs are not a new topic. So why are existing assurance tools falling short?
In the Present Mode of Operations (PMO), there are three key problems that traditional assurance solutions do not address well:
- Customers’ Interaction Management, Problem Handling and QoS/SLA management
In the PMO, customers have little to no insight into delivered service quality. Interactions with most assurance solutions today are not typically automated. Instead, they often require manual and time-consuming efforts. This leads to costly recurring and advanced problems.
- Service Problems and Quality Management
In the PMO, issues often go undetected because service quality must be inferred through device statistics. When there’s a lack of visibility into service quality and its impact on customers, it’s also difficult to prioritize issues.
- Business Partner Problems and Performance Handling
In the PMO, network operators don’t gain insight into partners’ networks. It’s extremely difficult to handle performance across these third-party clouds and networks because these environments aren’t directly managed and can create blind spots for operators. When issues arise, this can also lead to a lack of accountability, blame games and finger pointing.
The Typical Assurance Stack is Falling Short
In the typical assurance stack, most operations rely on a mix of solutions.
A fault and event management system presents volumes of alarms that show the operator if any devices are broken. Performance monitoring systems look at the overall network health while passive probes provide operators with a centralized understanding of traffic flows in the network and what protocols are enabled.
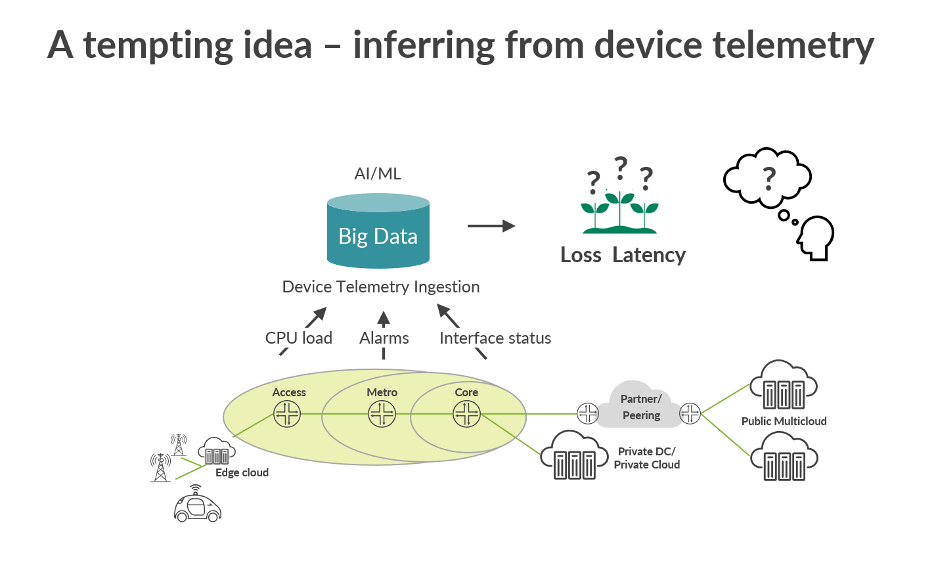
Significant investments have been made in device telemetry (i.e. for collecting CPU loads, alarms and interface status). This telemetry is stored in big data lakes, with network analytics, artificial intelligence (AI) and machine learning (ML) enabling operators to perform preventive maintenance and look at correlated faults of individual sections of the network. However, this device-centric approach cannot cost-effectively achieve sub-second insights into end-to-end data plane behavior.
Simply looking at device telemetry isn’t enough. Telemetry alone doesn’t provide the necessary network key performance indicators (KPIs) and end-to-end service KPIs. Rather, these KPIs need to be inferred using a large sum of device-specific statistics metrics. In this way, device telemetry is unable to truly measure and guarantee end-to-end network quality for services. Additionally, device telemetry data is often incomplete due to a lack of access to all devices along the service path, such as when it traverses partner domains and over-the-top services. It’s also difficult to map statistics from underlay to overlay – especially beyond fault and service impact toward service quality.
The typical assurance stack is ineffective in detecting a large majority of issues because most of the issues in a network are not faults – often, this is due to misconfigurations or non-optimal configurations. There’s no device alarm for a non-optimal QoS configuration or non-optimal routing policy/traffic engineering metric. Even misconfigured firewall rules can lead to silent performance issues that are difficult to pinpoint. These are the types of issues that can be discovered through testing on the data plane.
Both active and passive techniques may be used to monitor the data plane, but passive solutions, by nature, always put problem detection a step behind customers. With passive probes, it can be confirmed that the customer service is impacted, but there is no early warning to act proactively beforehand. Also, passive probing only works when there is actual user traffic, meaning that services cannot verified before users start consuming them. Passive probing cannot test and validate services before going into production. This type of solution becomes extremely costly. As overall traffic grows exponentially, so does the cost of passive solution to keep up with processing the increasing amount of traffic.
Measuring What Matters with Active Assurance
Active Assurance is different from classical assurance because it delivers direct insight into service quality KPIs. It provides a straightforward, service-centric approach that can provide immediate results regardless of the existing assurance stack being used.
Active Assurance works by measuring what matters directly: end-to-end service quality. It does this by actively sending a small amount of synthetic traffic on the data plane to simulate an end user. No management plane integration is required to perform active testing and the services being tested may also traverse through un-managed devices and partner networks. Synthetic active testing can be done across layers 2 to 7 to offer a comprehensive solution for proactively measuring unique per-service SLAs.
By measuring at the data plane instead of relying on telemetry collection, fine-grained, microsecond resolution times can be achieved. With active assurance, operators may measure true network KPIs instead of inferring them from device telemetry. These service KPIs can then be fed into big data lakes for network analytics and AI/ML to perform various use-cases, such as regression testing to predict what might happen in the future. AI/ML also enables more advanced anomaly detection and trend analysis, which can pinpoint intermittent jitter spikes that may be difficult to detect and could lead to service impacting problems.
Shift-left with Active Assurance
A shift-left testing approach is commonly seen in software testing and occurs when testing is performed earlier in the lifecycle. This approach can help overcome key operational challenges that classical assurance solutions cannot.
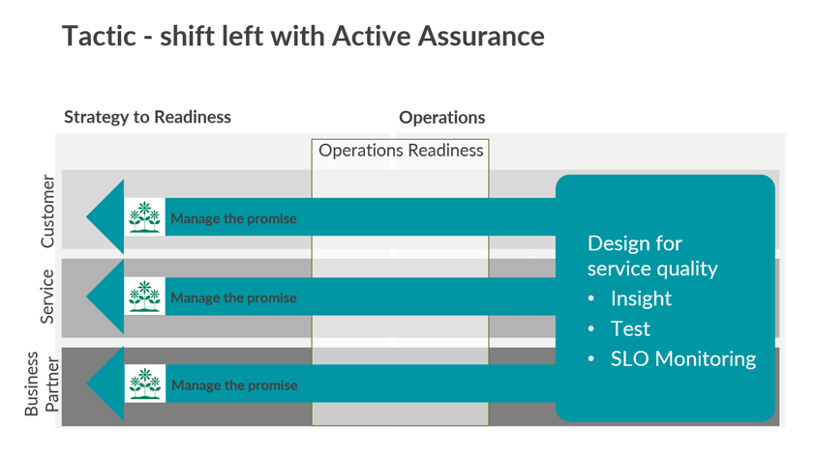
With a shift-left testing approach, active assurance can be incorporated earlier in the operations lifecycle starting at the operations strategy, design, readiness and setup phases, as well as during the service activation phase. By building active assurance into operational processes and network automation, these key problems can be solved in the following ways:
- Customers’ Interaction Management, Problem Handling and QoS/SLA management
With active assurance, operators can manage the service quality promise for customers through customer self-service portals with real-time service quality dashboards. This allows them to show their customers quality measurements and prove service quality is better than the competition.
- Service problem and quality management
With active assurance, operators can define and perform service quality tests on services up front. Testing and monitoring is enabled as part of the operational readiness processes in preparation for launching services and service activation testing can be performed in the fulfillment process. In addition, services can continue to be assured by performing proactive SLA monitoring with the right service level objective (SLO) priorities on a per-service basis.
- Business partner problem and performance handling
With active assurance, operators can define agreements for SLOs with their partners for third-party partner clouds and networks. They can perform network testing across partner networks during fulfillment and perform continual SLO monitoring for real-time insight across partner networks.
Using active assurance removes the blame game with partners and shortens mean-time-to-resolution (MTTR).
Active assurance enables operators to measure what matters directly, delivering true service performance visibility from an end-user perspective. It actively tests across end-to-end services that run over hybrid networks that may include SD-WAN, multi-domain WAN, multicloud and partner networks. This gives service operations a highly effective solution to identify, understand, troubleshoot and resolve issues before they impact services and customer experience.
Learn More
For more information on this topic and service assurance in the 5G and cloud era, read our solution brief and white paper and watch the TM Forum Webinar.
Related Articles:
- Converge! Network Digest Blueprint: Green network quality makes services operators happy
- FierceWireless: Active Assurance: Making service operations ready to assure quality in the 5G and cloud era
- FierceTelecom: Experience-first networking means proactively testing with active assurance
- FierceWireless: Assuring Service Quality End-to-End Across Third-Party, Partner and Peering Networks


