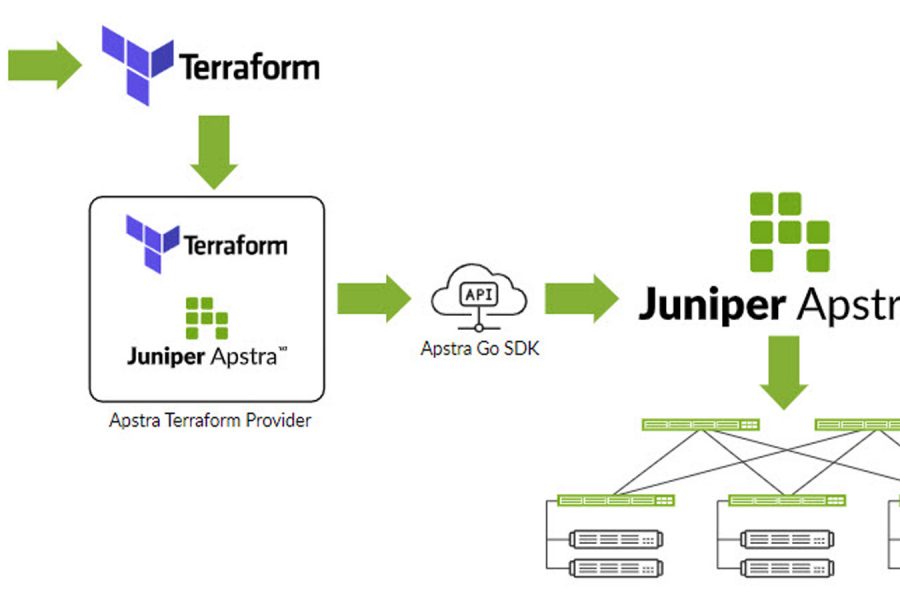
In a previous blog post I wrote about the need for simple building blocks to provide end-to-end connectivity in support of the multicloud promise. But multicloud does not end with connectivity. It requires orchestration, end-to-end visibility and pervasive security. And those additional top-to-bottom requirements are just as important as having end-to-end reach.
The underlying objective for all multicloud architectures has to be providing infrastructure while simultaneously tackling the crippling complexity challenges of the changing IT landscape.
Invisible infrastructure
The primary purpose of multicloud is to allow workloads to run wherever they need to satisfy economic or experience requirements. But if this flexibility comes at the expense of losing a seamless experience for users, multicloud will have been a failure.
Infrastructure should ultimately be invisible. Users should not care whether a workload is running in AWS or Azure, on-premises or off-premises. In many ways, it’s like public utilities. When you turn on your faucet, water appears. You don’t think about where the water is sourced, how it is pumped or how it arrives to you. Similarly, application users should not need to worry about the differences in the underlying infrastructure—they should care only that the application is doing what they need at the moment they need it.
Overlays for dynamic policy
Of course, providing dynamic, end-to-end policy and control is difficult. Network infrastructures traditionally have been statically segmented to offer control and policy boundaries. Any change in policy or migration of users and workload have required significant changes to static network segmentation and policy boundaries, one network device and firewall at a time. This is very complex, error-prone and anything but fast.
This is a big reason why overlays have emerged. If the underlying network is static, then an overlay network allows for the more rapid policy changes required in an environment where users and workloads are not permanently pinned to a set of resources.
To make this more clear, networking’s solution to complexity was not to simplify policy management across network segments. Rather, the designed solution was adding a separate overlay network on top of the physical network and then separating the management of the two into different administrative domains. Overlay networking is powerful, but there is a complexity tax that operators pay when they are forced to manage the overlay as a separate resource.
How does this fundamentally reduce complexity?
Design simply
If the macro trend to be addressed is complexity, then policy and control need to be solved, but in a way that reduces complexity.
Juniper Networks believes that policy and security should be managed in the same way, regardless of whether the underlying resource is bare metal or virtual, underlay or overlay, running on merchant silicon or custom silicon, on-premises or off-premises, in a public cloud or a private cloud – and even Juniper or non-Juniper.
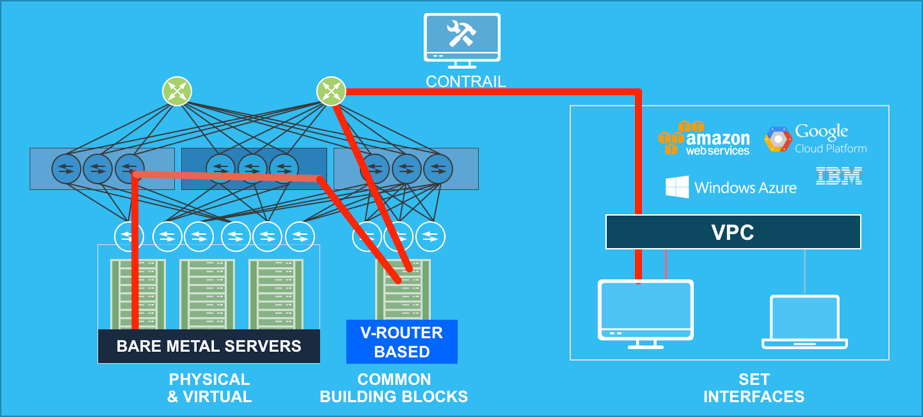
By providing a common orchestration layer that functions across a diverse set of application environments and network infrastructure, both physical and virtual, Juniper is reducing the ways to manage policy within the network. A consistent operating model is the right design for greater simplicity. That’s what makes the underlying infrastructure invisible.
The cost of complexity
The cost of complexity is more than just the cost of buying another tool. Different operating environments force staff to be especially vigilant as they manage the infrastructure.
It simply cannot be that a workflow fundamentally changes depending on where an application runs. How can enterprises keep up with the demands of the business if they have to be hyper-contextually aware?
This burden results in longer times to complete tasks, but perhaps more importantly, it increases the likelihood of something going wrong. When the underlay and overlay are completely separate, it forces a human in the middle to act as the unifier, a position that is unusually prone to error. And what enterprise is satisfied with increasing the odds of creating a problem?
Learning from DevOps
One of the central principles of DevOps in a continuous integration and delivery model is that staging and production need to be identical. When staging is not the same as production, it forces another round of validation before pushing a change out, which is decidedly not DevOps.
The same management model is true for policy. If the underlay and overlay are completely divorced, it creates a gap between the two worlds. That gap has to be filled by judgement—an individual who determines whether a change is acceptable or not.
If multicloud means dynamic infrastructure that is invisible to the users, having a common orchestration layer that spans both underlay and overlay seems a prudent way to plan for speed. Replace human judgment with a system that holds knowledge so that the technology can do the work.
In other words, use engineering to guarantee simplicity.