En enero de 2024, Juniper presentó la Plataforma de redes nativas de la IA para hacer uso de los datos relevantes a través de la infraestructura relevante para brindar las respuestas relevantes tendientes a ofrecer experiencias óptimas de usuarios y operadores. Utilizando IA para operaciones de redes simplificadas (IA para redes) y estructuras Ethernet optimizadas para IA a fin de mejorar la carga de trabajo de IA y el rendimiento de la GPU (redes para IA), Juniper cumple nuestro compromiso con los clientes de establecer redes que prioricen la experiencia.
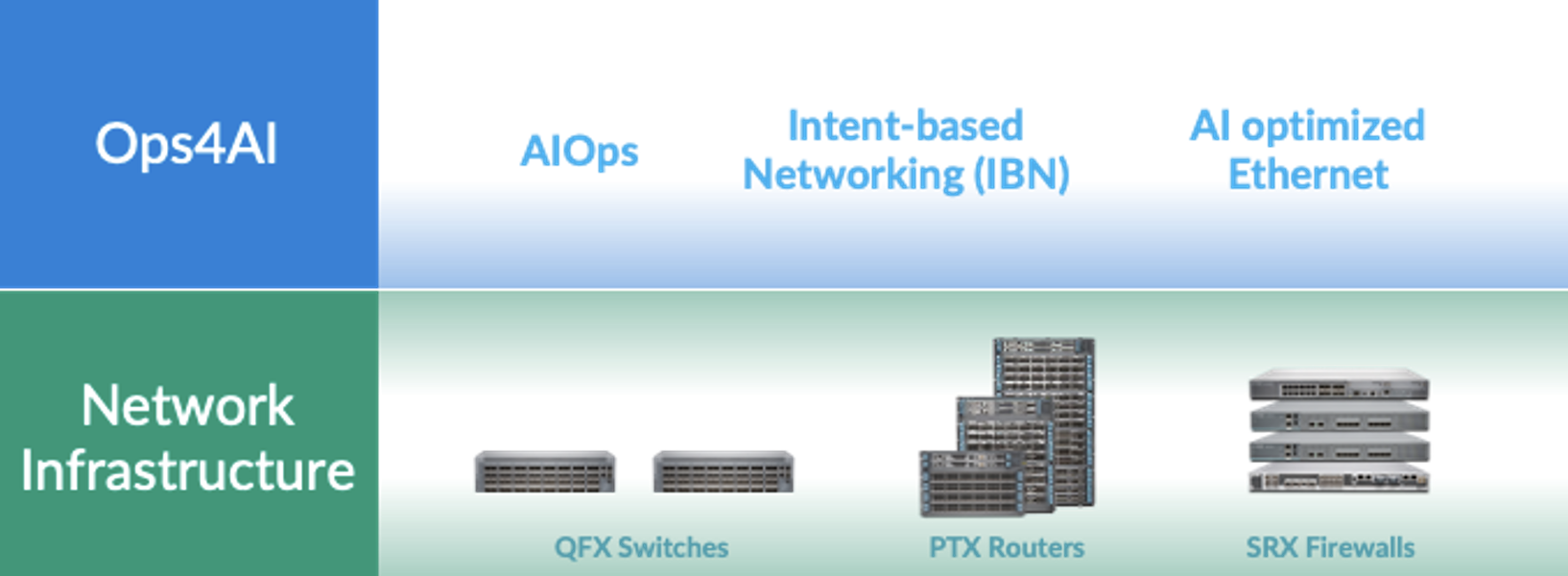
Basándonos en nuestro rico historial en proporcionar infraestructuras de red de centro de datos seguro de alto rendimiento, que consta de conmutadores QFX, enrutadores PTX y cortafuegos SRX, Juniper se enorgullece de anunciar una extensión de nuestra arquitectura de redes nativas de la IA que brinda a los clientes operaciones integrales y de múltiples proveedores para AI Data Centers. Nuestra nueva solución, Ops4AI, ofrece mejoras impactantes que brindarán un valor significativo a los clientes. Ops4AI incluye una combinación única de los siguientes componentes de Juniper Networks:
- AIOps en el centro de datos basado en el Marvis Virtual Network Assistant
- Automatización basada en intenciones a través de la gestión de estructuras de centros de datos de múltiples proveedores Juniper Apstra
- Capacidades de Ethernet optimizadas para IA, incluidos RoCEv2 para IPv4/v6, gestión de congestión, equilibrio de carga eficientey telemetría.
En conjunto, la Ops4AI permite la rápida aceleraración del tiempo de obtención de valor de los AI Data Centers de alto rendimiento, al mismo tiempo que reduce los costos operativos y optimiza los procesos. Y ahora la solución está mejorando aún más con la incorporación de varias mejoras nuevas: Un nuevo Juniper Ops4AI Lab de múltiples proveedores, abierto a los clientes para probar cargas de trabajo y modelos de IA privados y de código abierto; diseños validados de Juniper que aseguran la conexión en redes para configuraciones de IA utilizando Juniper, Nvidia, Broadcom, Intel, Weka y otros socios; y mejoras en el software Junos y Apstra para redes de centros de datos optimizadas para IA, un foco principal de este blog.
Veamos las nuevas mejoras del software Junos® y Juniper Apstra. Incluyen lo siguiente:
Afinado automático de la estructura para IA
El acceso remoto a la memoria dinámica (RDMA) desde las GPU impulsa un masivo tráfico de red en las redes de IA. A pesar de las técnicas para evitar la congestión, como el equilibrio de carga, existen situaciones en las que hay congestión (por ejemplo, tráfico desde varias GPU que va a una sola GPU en el último salto de conmutador). Cuando se produce esto, los clientes utilizan técnicas de control de congestión como la Notificación de congestión cuantificada del centro de datos (DCQCN). La DCQCN utiliza características como Notificación de congestión explícita (ECN) y Control de flujo basado en prioridades (PFC) para calcular y configurar ajustes de parámetros a fin de obtener el mejor rendimiento para cada cola de cada puerto en todos los conmutadores. Ajustarlos manualmente en todas las miles de colas en todos los conmutadores es difícil y engorroso.
Para abordar este problema, Apstra recopila regularmente la telemetría de cada una de estas colas para cada uno de los puertos. Esa información de telemetría se utiliza para calcular los ajustes óptimos de los parámetros ECN y PFC para cada cola de cada puerto. Mediante la automatización de circuito cerrado, se configuran los ajustes óptimos en todos los conmutadores de la red.
Esta solución proporciona los ajustes óptimos de control de congestión, simplificando significativamente las operaciones y ofreciendo menor latencia y menores tiempos de finalización de trabajos (JCT). Nuestros clientes están invirtiendo tanto en infraestructura de IA que ahora estas características están disponibles en Juniper Apstra sin costo adicional. Para ver detalladamente cómo funcionan, le ofrecemos una demostración de la edición más reciente de Día de campo en la nube. También cargamos esta aplicación en GitHub.
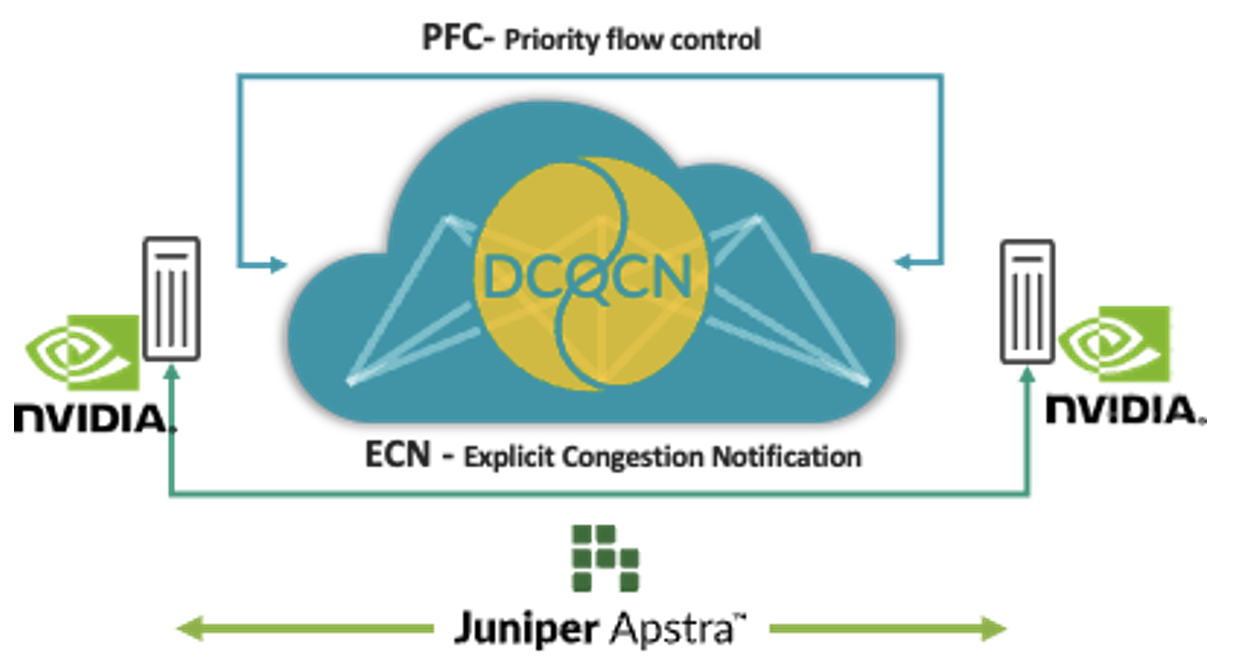 Figura 1: Afinado automático de la estructura para IA
Figura 1: Afinado automático de la estructura para IA
Equilibrio de carga global
El tráfico de redes de IA tiene características únicas. Está impulsado principalmente por el tráfico RDMA de las GPU, lo que genera un gran ancho de banda y menos flujos, pero más grandes (a menudo denominados flujos de elefante). Como consecuencia, el equilibrio de carga estático basado en hash de 5 tuplas no funciona bien. Múltiples flujos de elefantes se mapean al mismo vínculo y causan congestión. Esto genera JCT más lentos, lo cual es abrumador para las grandes inversiones en GPU.
Para abordar el problema, se dispone del equilibrio de carga dinámico (DLB). El DLB tiene en cuenta el estado del vínculo ascendente en el conmutador local.
En comparación con el equilibrio de carga estático tradicional, el DLB mejora significativamente la utilización del ancho de banda de la estructura. Pero una de las limitaciones del DLB es que solo rastrea la calidad de vínculos locales en lugar de comprender la calidad de la ruta completa desde el nodo de entrada hasta el de salida. Digamos que tenemos una topología CLOS y que el servidor 1 y el servidor 2 tratan de enviar datos llamados flujo-1 y flujo-2, respectivamente. En el caso del DLB, la leaf-1 solo conoce la utilización de vínculos locales y toma decisiones basándose únicamente en la tabla de calidad del conmutador local donde los vínculos locales pueden estar en perfecto estado. Pero, si se usa GLB, se puede comprender la calidad de la ruta completa donde haya problemas de congestión dentro del nivel de spine-leaf.
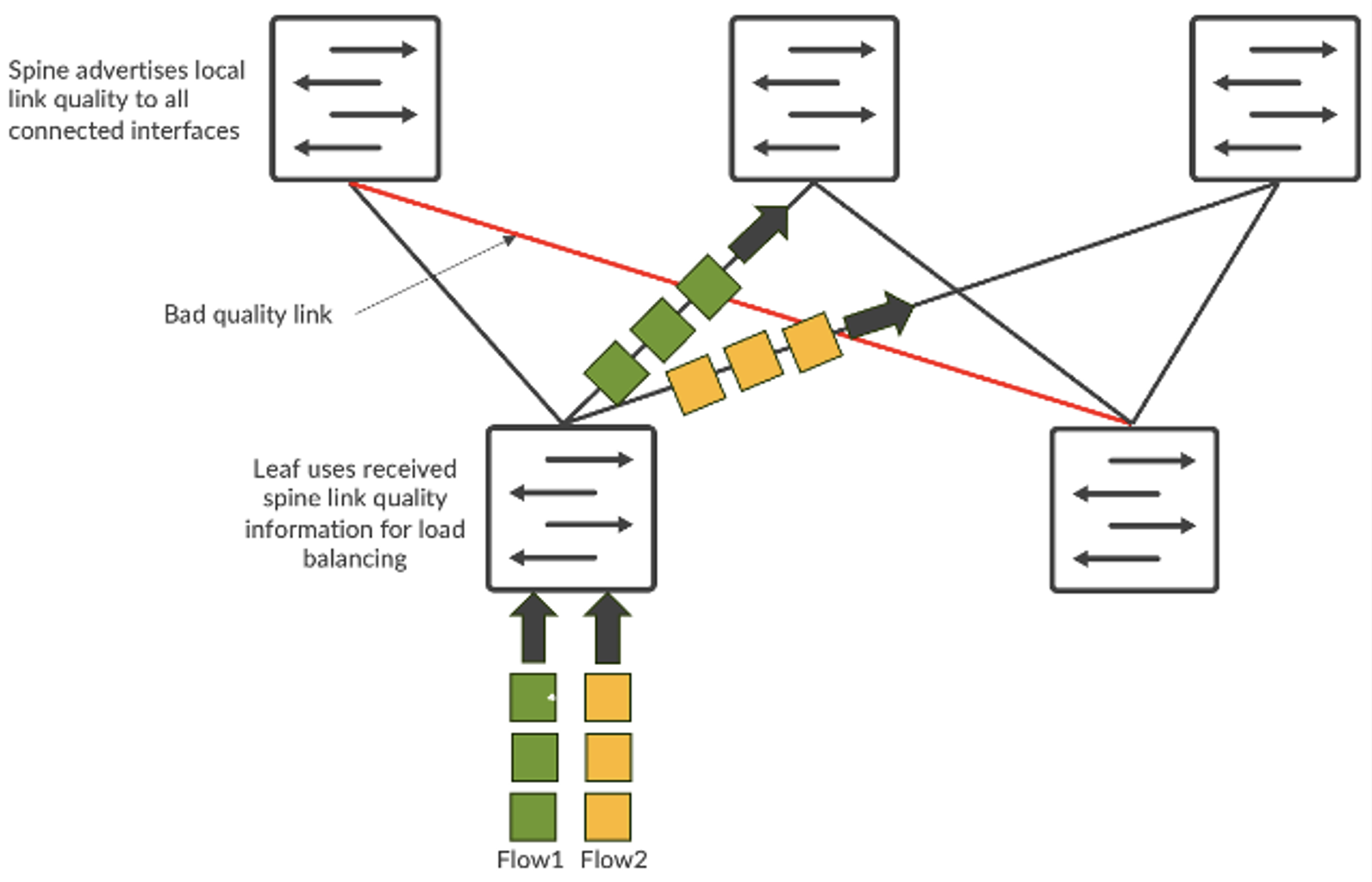 Figura 2: Equilibrio de carga de los flujos
Figura 2: Equilibrio de carga de los flujos
Es similar a Google Maps, donde la ruta seleccionada se basa en una vista integral.
Esta característica selecciona la ruta de red óptima y ofrece menor latencia, mejor utilización de la red y JCT más rápidos. Desde la perspectiva de las cargas de trabajo de la IA, esto genera un mejor rendimiento de las cargas de trabajo de la IA y una mayor utilización de GPU costosas.
Visibilidad integral desde la red hasta las SmartNIC
Hoy en día, los administradores pueden descubrir dónde se produce la congestión observando únicamente los conmutadores de red. Pero no tienen visibilidad alguna sobre qué puntos de conexión (GPU, en el caso de los AI data centers) se ven afectados por la congestión. Esto conduce a desafíos para identificar y resolver problemas de rendimiento. En un entorno de trabajo de entrenamiento múltiple, con solo observar la telemetría del conmutador, es imposible encontrar qué trabajos de entrenamiento se han ralentizado debido a la congestión sin verificar manualmente las estadísticas de NIC RoCE v2 en todos los servidores, lo cual no es práctico.
Para abordar el problema, la integración de la telemetría enriquecida de transmisión en continuo de RoCE v2 desde las SmartNIC del servidor de IA hasta Juniper Apstra y la correlación de la telemetría del conmutador de red existente mejora en gran medida la observabilidad y los flujos de trabajo de depuración cuando se producen problemas de rendimiento. Esta correlación permite una visión más holística de la red y una mejor comprensión de las relaciones entre los servidores de IA y los comportamientos de la red. Los datos en tiempo real brindan información sobre el rendimiento de la red, los patrones de tráfico, los posibles puntos de congestión y los puntos de conexión afectados, lo que ayuda a identificar cuellos de botella y anomalías en el rendimiento.
Esta capacidad mejora la observabilidad de la red, simplifica la depuración de problemas de rendimiento y ayuda a mejorar el rendimiento general de la red mediante la adopción de acciones de circuito cerrado. Por ejemplo, monitorear los paquetes fuera de orden en las SmartNIC puede ayudar a afinar los parámetros en la característica de equilibrio de carga inteligente en el conmutador. Por lo tanto, la visibilidad integral puede ayudar a los usuarios a ejecutar la infraestructura de IA al máximo rendimiento.
 Figura 3: Visibilidad E2E desde la red hasta las SmartNIC
Figura 3: Visibilidad E2E desde la red hasta las SmartNIC
Para obtener más información, asegúrese de participar en “Seize the AI Moment”, nuestro evento en línea, el 23 de julio, donde contamos con un grupo estelar de clientes de Juniper y luminarias de la industria para hablar sobre lo que han aprendido en el mundo en rápido desarrollo de la infraestructura de AI data center.
Declaración de orientación del producto Juniper Networks puede divulgar información relacionada con el desarrollo y los planes para futuros productos, características o mejoras, conocida como Declaración de orientación del producto o Plan de registro (“POR”). Estos detalles brindados se basan en los esfuerzos y planes de desarrollo actuales de Juniper. Estos esfuerzos y planes de desarrollo están sujetos a cambios a discreción exclusiva de Juniper sin previo aviso. Con excepción de lo que podría establecerse en un acuerdo definitivo, Juniper Networks no brinda ninguna garantía ni asume responsabilidad alguna en presentar productos, características o mejoras descritos en este sitio web, presentación, reunión o publicación. Además, Juniper tampoco es responsable de ninguna pérdida que surja de la confianza en el POR. Las decisiones de compra de terceros no deben basarse en este POR y ninguna compra depende de que Juniper Networks entregue alguna característica o funcionalidad descrita en este sitio web, presentación, reunión o publicación.


