Intelligent load balancing of AI/ML workloads
AI/ML workloads in data centers generate distinct traffic called “Elephant flows.” These large amounts of remote direct memory access (RDMA) traffic are typically produced by graphics processing units (GPUs) in AI servers. To understand why these GPUs generate these Elephant flows, it’s essential to understand the crucial role that data plays in AI training, such as large language models (LLMs), image classification, video-audio analysis and more.
A Simple Explanation of the Bigger Task
In the training phase, the first step is to gather raw data from different sources such as Wikipedia, specific databases, cloud storage, etc. Then, data scientists or engineers process the data to label or tokenize each piece. These tokens/data sets/inputs are then trained to produce the expected outcomes. For example, we want relevant answers in an LLM when we type a query online. To do this, we need to train the dataset, which is usually big and heavy. So, we need a lot of GPUs to train the model, and we are dealing with more than petabytes of data. Usually, these big/heavy data are split into batches and use some parallel mechanisms (data parallelism/model parallelism, to name just two). After the processed data is fed to the training model, the GPU cluster performs arithmetic calculations/training to get the desired result. Each GPU training calculation’s output must be synchronized with other GPUs in the cluster to have a harmonized view. This is done by sending the output of every GPU training result to all other GPUs in the cluster. This traffic flow (memory transfer) uses special storage transport protocols like RoCEv2, and we call this traffic flow the Elephant flow.
Rocking with RoCE
In order to train models on our AI backend infrastructure, we use GPU clusters to perform complex mathematical calculations (floating point operations or FLOPS) and generate vast amounts of results in parallel; thereby, we can speed up the delivery and training of AI models. When moving from one job to another, the training models’ gradients/memory chunks must be transferred from one GPU to other GPUs in the cluster to have synchronized output. So, to synchronize these results between distributed GPU servers, we use the RoCEv2 transport protocol, also known as RDMA over Converged Ethernet – version 2. RoCEv2 has become a popular protocol for data transport because it does not require the GPU NIC to maintain the state or involve the server CPU. Therefore, it scales better than any TCP-based data transport like NVMEoTCP, which is used only in conventional storage data networks.
Also, the new evolution of software developments around LLMs and other domain-specific training models use parallel computing power at different server nodes and continuously synchronizes their states before finishing their job. This translates to enormous east-west data exchange across the DC backend fabric on an Ethernet network. So, we need to ensure the fabric bandwidth utilization is efficient and works well even in situations of low entropy workloads. That’s why it’s instrumental for the backend AI data center network to guarantee the following characteristics:
- Effective IP ECMP load-balancing (LB), with multiple 400G/800G links between leaf and spine. Additionally, large data pieces are being transferred east-west between the server’s GPUs. So, the whole fabric bandwidth must be used well to sync all of the data without losing any frames.
- Congestion management and mitigation techniques—PFC-DSCP (Priority Flow Control) and ECN (Explicit Congestion Notifications)—and coordination of both techniques through the DCQCN.
Load Balancing Techniques
In this blog, I focus on efficient load balancing techniques within the AI data center fabric. There are various ways to enhance load balancing efficiency, some of which use only the local node-level awareness of link quality and some of which use both local link and remote node quality performances to select the optimal path. These techniques can be categorized into four different approaches to load balancing:
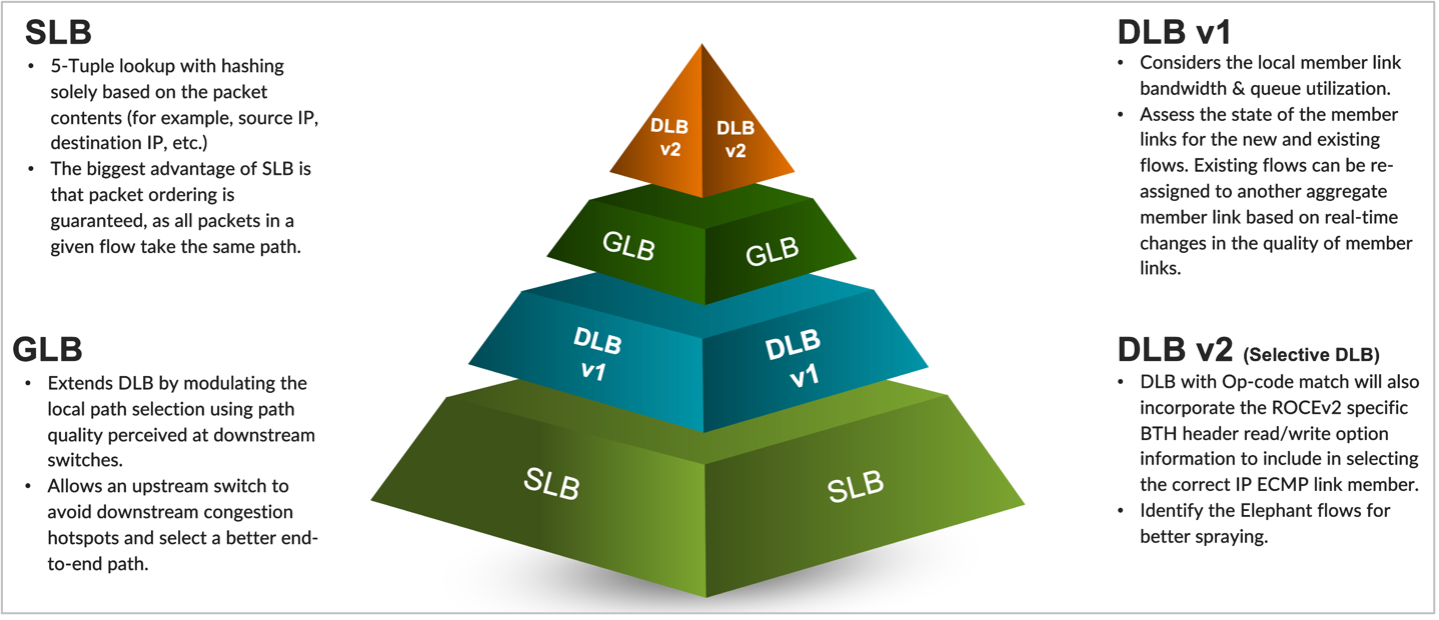
- Option 1: Static load balancing (SLB) is typically not used in the context of AI/ML fabric. This is because this legacy load balancing technique only considers the packet format and packet entropy characteristics rather than evaluating the real-time usage of the IP ECMP member links and their queues.
- Option 2: Dynamic load balancing (DLB) considers the local link bandwidth utilization and the queue size at the given fabric node level. This helps to not only select the optimal link but also a healthy and correct link for the flow, ensuring a smooth flow of traffic.
- Option 3: Global load balancing (GLB) uses a path selection algorithm that includes the next-to-next-hop (NNH) information on the link quality (including the local leaf but also the spine link’s ability to select the best member link to use for the new or existing flows), along with link-local bandwidth and queue sizes.
- Option 4: DLB v2 or selective DLB enables the identification of flow and spray packets for specific flows. The Op-code match also includes the RoCEv2-specific BTH header read/write Op-code information.
Static Load Balancing (SLB)
Static load balancing (SLB) is commonly used in the Ethernet switching and routing industry to balance network traffic between different links and ensure effective bandwidth usage. It worked well for traditional server deployments where many different applications were used. SLB is based on computing the hash value from the features of the packet header. In Ethernet frames, the Ether-type header contains the source/destination IP, the source/destination UDP/TCP transport layer, and the protocol type to have entropy. This quintuple load balancing hash might seem enough, but unfortunately, it’s not always suitable for AI servers and RDMA GPU traffic. The RDMA traffic will have very low entropy—which means a low level of variation inside the packets, making the flows always use the same link. The SLB mechanism does not consider the local link bandwidth usage and queue depth, and neither does it check the link health before assigning the flow to the link. This means that a link carrying high bandwidth may be assigned a new flow while a link that is free remains underutilized. To address these issues, alternative load balancing methods may need to be considered for AI and GPU traffic.
Dynamic Load Balancing (DLB)
Dynamic load balancing (DLB) considers the local member link bandwidth and queue utilization and the state of the member links for the new and existing flows. DLB has two main modes: flow-let and per-packet mode. When considering the bandwidth local utilization for selecting the outgoing IP ECMP group interfaces, we must decide whether the selection will happen at the per-packet or per-flow level.
- In the per-packet spraying mode, packets from the same flow are sprayed across the link members of the IP ECMP group. This mode requires support from NIC to re-order packets.
- The flow-let mode is where the active flow takes an outgoing interface based on the current bandwidth utilization.
- The assigned flow mode isolates the problem sources. It can be used to selectively disable rebalancing for a period of time. Assigned flow mode does not consider port load or queue size.
Per-packet load balancing is a challenging task. The decision is made for each datagram of the same flow at the switch silicon, and individual packets are spread across all IP ECMP links. Also, the server NIC needs to ensure the re-ordering of the out-of-order packets. In the flow-let mode, the longevity of the selection is higher, and the switch usually has fewer decisions to make. Also, NIC cards on the servers won’t have to take care of the reordering tasks.
When the switch is enabled with DLB, it will maintain a unique table called the local port quality table at the ASIC level and map packets or flows to different outgoing ports. From the ASIC’s perspective, the port quality table will be updated regularly based on the state of the interfaces. DLB periodically receives port load and queue size from each member port in the aggregate group. These values are input to the DLB algorithm. The algorithm’s output is a quality band number, which will be assigned to the port. Usually, there are eight quality bands (0-7) supported, with the quality band number “7” indicating the highest quality and the quality band number “0” indicating the lowest quality.
Global Load Balancing (GLB)
Dynamic load balancing is a great improvement and significantly enhances fabric bandwidth utilization compared to traditional static load balancing. However, one of the limitations of DLB is that it only tracks the quality of local links rather than understanding the whole path quality from ingress to egress node. Let’s say we have CLOS topo, and server 1 and server 2 are both trying to send data called flow-1 and flow-2, respectively. In the case of DLB, leaf-1 knows only the local links utilization and makes decisions based only on the local switch quality table, where local links may be in perfect state. However, in the case of GLB, we can understand the whole path quality where congestion issues are present within the spine-leaf level.
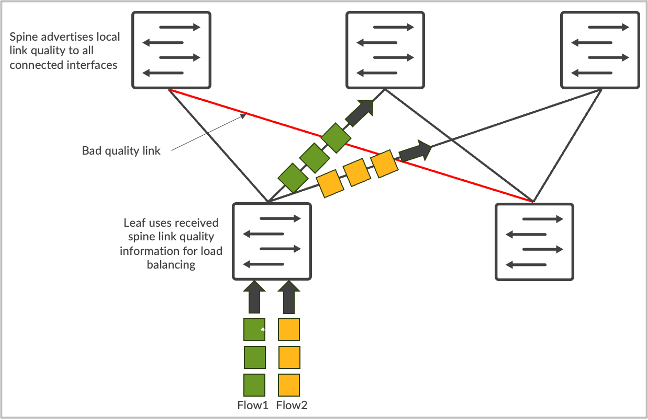
In an AI data center fabric, the best practice is to create remote link quality tables in addition to the local link quality. This is particularly useful since spines aggregate the traffic from many leaf nodes and will be the most common place where link quality degradation will occur. The challenge with implementing GLB is that the information must be updated regularly at the micro-second level, which might not be possible using a CPU-based kernel implementation of a control plane protocol unless it is fully distributed to the hardware ASIC of the switch. This is similar to the BFD implementation in the industry, which evolved from centralized to fully distributed hardware implementations.
DLB v2 (Selective DLB)
In the previous DLB option, we’ve seen the main characteristics of the two possible dynamic load balancing modes—flow-let and per-packet spraying. In this DLB v2 mode, we will identify specific flows and spray packets for them. We can use user-defined filters to identify a specific flow and map those filters into DLB with an Op-code match on the RoCEv2 BTH header.
This is typically a good option to get different treatments of the packets from the server, but it requires a good understanding of the flow characteristics and some TCAM space allocation to enable specific treatment of the packet based on the access list’s enabled ingress at the switch. As mentioned in the earlier section, packet mode may cause out-of-order packets, which may not be desirable for all flows. Certain opcodes can handle OOO packets (with NIC support). Typically, the same rule can be applied for specific storage or data synchronization operations in the context of the AI DC network, where specific RoCEv2 opcode values can be selected and used as ACL matching criteria to enable one or the other mode of load balancing. The switch ASIC also must support the specific customizations and take action from the ACL to enable specific load balancing modes.
A Comparative View of the Load Balancing Mechanisms
Let’s summarize the different load balancing methods and compare them based on their specific capabilities. When considering IP CLOS fabrics with 400Gbps/800Gbps and soon the 1.6Tbps per port deployments, the link speed and how it’s utilized are both important. Some of the methods may be important for specific use cases. However, others are less important; therefore, a basic load balancing mechanism such as SLB may be good enough. However, in more complex deployments, such as in AI/ML data centers, DLB and GLB will deliver the best packet forwarding performances and the most efficient bandwidth utilization.
Some of the AI/ML network load balancing techniques mentioned above can be enabled in parallel. For instance, DLB is applied locally at the node while delivering the GLB or when multiple links are enabled inside a particular fabric. In AI data center implementations, the network architects have the freedom to choose the type of RoCEv2 operations (BTH opcodes) the given load balancing method will enable. It’s also important to understand that the effectiveness of the load balancing technique is highly dependent on the silicon. This is because traffic and load balancing should be executed at the micro-second or nano-second level, requiring quick processing times.
Load balancing has been a common practice in data centers for many years. This is because data centers usually have high application diversity and a high number of flows entering the same switch, as well as mixed east-west and north-south communications. However, traditional load balancing methods are unsuitable for the newer AI/ML backend data center networks. In the case of AI/ML cluster switching infrastructure, the typical communication pattern is east-west, and the number of applications running in the backend Ethernet is relatively low. Typically, only RoCEv2 transport is used and nothing else with reference to the applications. This is why more recent developments in dynamic load balancing rely on bandwidth utilization on the IP ECMP group. Local bandwidth utilization is used in the case of DLB, and local and remote are used for the GLB. We expect to see more advanced capabilities in load balancing on the market in the coming years.
