KI-Modelle zu trainieren ist eine besondere Herausforderung. Die Entwicklung von grundlegenden Large-Language-Modellen (LLMs), wie Llama 3.1 und GPT 4.0, erfordert enorme Budgets und Ressourcen, die nur eine Handvoll der größten Unternehmen der Welt aufbringen können. Diese LLMs enthalten Milliarden oder sogar Billionen von Parametern, die komplexe Datencenter-Fabric-Feinabstimmung erfordern, wenn Ihr Training in einer angemessenen Zeit abgeschlossen werden soll. GPT 4.0 verwendet zum Beispiel 1,76 Billionen Parameter!
Um zu verdeutlichen, was diese Zahlen bedeuten, stellen Sie sich jeden Parameter als eine Spielkarte vor. Ein Spiel mit 52 Karten ist etwa 2 cm dick. Ein Stapel mit einer Millionen Karten wäre höher als das Empire State Building, ein Stapel mit einer Milliarde Karten würde 367.000 m hoch in die Thermosphäre der Erde ragen und ein Stapel mit einer Billiarde Karten wäre mehr als 365.321.000 m hoch, was etwa der Entfernung zum Mond entspricht.
KI-Investitionen optimal nutzen
Viele Unternehmen brauchen im Bezug auf Investitionen in KI einen neuen Ansatz: Die Verfeinerung dieser grundlegenden LLMs mit ihren eigenen Daten zur Lösung spezieller Geschäftsprobleme oder um die Kundenbindung zu vertiefen. Da die Einführung von KI jedoch im Mittelpunkt steht, wünschen Unternehmen sich neue Wege, ihre KI-Investitionen optimal zu nutzen, um dadurch mehr Datenschutz und eine stärkere Differenzierung der Serviceerfahrung zu erreichen.
Für die meisten Unternehmen heißt das, dass sie einen Teil ihrer lokalen KI-Workloads in private Datencenter verschieben müssen. Die laufende Debatte zum Thema „Public-Cloud- vs. Private-Cloud-Datencenter“ gilt auch für KI-Datencenter. Für viele Unternehmen ist die Entwicklung einer KI-Infrastruktur Neuland und schüchtert sie ein. Es gibt Herausforderungen, aber sie sind nicht unüberwindbar. Vorhandenes Wissen über Datencenter kann angewendet werden. Alles was Sie brauchen, ist ein wenig Hilfe und Juniper begleitet sie.
In dieser Serie von Blogbeiträgen untersuchen wir verschiedene Aspekte, die Unternehmen erwägen müssen, die in KI investieren, und wie das ABC der KI-Datencenter von Juniper unterschiedliche Ansätze unterstützt: Applications (Anwendungen), Build (Entwicklung) vs. Buy (Kaufen) und Cost (Kosten).
Aber schauen wir uns zunächst an, warum eine KI-Infrastruktur eine Spezialisierung benötigt.
LLMs und neuronale Netzwerke verstehen
Um Infrastrukturoptionen besser zu verstehen, ist es hilfreich, einige Grundlagen der KI-Architektur und die grundlegenden Kategorien von KI-Entwicklung, -Bereitstellung, -Training und -Inferenz zu verstehen.
Inferenzserver werden in Frontend-Datencentern gehostet, die mit dem Internet verbunden sind, wo Benutzer und Geräte eine vollständig trainierte KI-Anwendung (z. B. Llama 3) abrufen können. Unter Verwendung des TCP spiegeln Inferenzabfragen und Verkehrsmuster diejenigen von anderen in der Cloud gehosteten Workloads wider. Inferenzserver können herkömmliche Rechnerverarbeitungseinheiten (CPUs, Computer Processing Units) oder dieselben Grafikverarbeitungseinheiten (GPUs, Graphic Processing Units), die beim Training verwendet wurden, nutzen, um in Echtzeit die schnellste Reaktion mit der niedrigsten Latenz bereitzustellen. Gemessen wird dieser Vorgang üblicherweise mit Kennzahlen wie der Time-to-first-Token und der Time-to-incremental-Token. Im Wesentlichen zeigen diese Kennzahlen, wie schnell das LLM auf Anfragen reagieren kann und ob beträchtliche Investitionen und Fachwissen nötig sind, um eine konstante Leistung aufrechtzuerhalten.
Im Training hingegen existieren einzigartige Herausforderungen, die spezielle Datencenter-Architekturen erfordern. Das Training findet in Backend-Datencentern statt, wo LLMs und Trainingsdatensätze vom „unseriösen“ Internet isoliert sind. Diese Datencenter verfügen über leistungsstarke GPU-Rechenleistungs- und -Speicherplattformen mit hoher Kapazität und speziellen Rail-optimierten Fabrics, die Netzwerkverbindungen mit 400 GBit/s und 800 GBit/s verwenden. Wegen großen „Elephant Flows“ und umfangreicher GPU-zu-GPU-Kommunikation müssen diese Netzwerke dazu optimiert sein, mit der Kapazität, den Verkehrsmustern und den Verwaltungsanforderungen des Datenverkehrs von kontinuierlichen Trainingszyklen umzugehen, deren Fertigstellung Monate dauern kann.
Wie viel Zeit bis zum Abschluss des Trainings erforderlich ist, hängt von der Komplexität des LLM, den Schichten innerhalb des neuronalen Netzwerks zum Training des LLM, der Anzahl von Parametern, die verfeinert werden müssen, um die Genauigkeit zu verbessern, und dem Design der Datencenter-Infrastruktur ab. Doch was genau sind neuronale Netzwerke und welche Parameter verfeinern die LLM-Ergebnisse?
Neuronale Netzwerke 101
Bei einem neuronalen Netzwerk handelt es sich um eine Rechenarchitektur, deren Zweck es ist, das Berechnungsmodell des menschlichen Gehirns nachzuahmen. Sie werden in einem Satz von progressiven, funktionellen Ebenen implementiert. Dieser Satz umfasst eine Eingabeebene zum Erfassen von Daten, eine Ausgabeebene zur Präsentation von Ergebnissen und verborgene Ebenen in der Mitte, die Rohdateneingaben zu verwendbaren Informationen verarbeiten. Die Ausgabe einer Ebene wird zur Eingabe für eine andere Ebene, sodass Anfragen in jeder Ebene systematisch zerlegt, analysiert und über mehrere Sätze von neuronalen Knoten oder mathematischen Funktionen verarbeitet werden können, bis Ergebnisse erbracht werden.
Das nachfolgende Bild repräsentiert beispielsweise ein LLM, das mit einem neuronalen Netzwerk trainiert wird, um die handgeschriebenen Ziffern der ersten vier geraden Zahlen zu erkennen. Dieses neuronale Netzwerk verfügt über zwei verborgene Ebenen, eine zum Verarbeiten der Formen und die andere zum Erkennen von Mustern. Datensätze mit handgeschriebenen Zahlen werden in kleinere Blocks zerlegt und in das Modell eingegeben, wo in der ersten Ebene Kurven und Linien funktionell verarbeitet werden, bevor sie an die zweite Ebene gesendet werden, um die Muster in den Daten zu erkennen, die möglicherweise anzeigen, welche Zahl gerade analysiert wird.
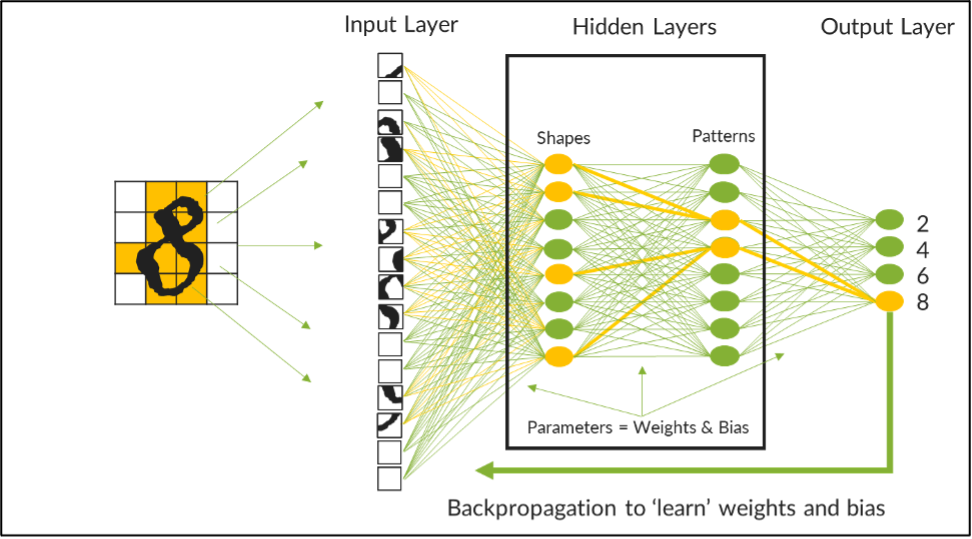
Feinabstimmungsparameter für optimale Genauigkeit des LLM
Neuronale Knoten innerhalb jeder Ebene verfügen über ein Netz aus neuronalen Netzwerkverbindungen, die KI-Wissenschaftlern ermöglichen, Gewichte auf jede Verbindung anzuwenden. Jedes Gewicht ist ein numerischer Wert, der die Stärke des Zusammenhangs mit einer gegebenen Verbindung anzeigt. Eine Kurve in einem oberen Quadranten der Daten hätte beispielsweise ein höheres Gewicht in Richtung einer 2 oder einer 8, während eine Linie im selben Quadranten für denselben Wert ein niedrigeres Gewicht hätte. Wenn man sich die Muster ansieht, kann ein Satz aus vertikalen und geraden Linien eine stärkere Verbindung und ein höheres Gewicht in Richtung einer 4 aufweisen, während Linien und Kurven zusammen eine stärkere Verbindung und ein höheres Gewicht in Richtung einer 2, 6 oder 8 aufweisen.
Am Anfang des Trainings sind die Ergebnisse des Modells unglaublich ungenau. Doch mit jedem Trainingsdurchgang können die Gewichte dieser neuronalen Verbindungen angepasst oder „verfeinert“ werden, und die Genauigkeit progressiv zu erhöhen. Um starke Verbindungen noch deutlicher von schwachen zu trennen, wird ein numerischer Bias auf jede Verbindung angewendet, um starke Verbindungen zu verstärken und negative Verbindungen zu verwalten. Gemeinsam repräsentieren Gewichte und Bias die Parameter, die abgestimmt werden müssen, um die Genauigkeit eines LLM zu verfeinern.
In diesem schlichten Beispiel gibt es 242 Parameter, die wiederholt verfeinert werden müssen, bevor das Modell jede Zahl mit einem hohem Maß an Genauigkeit identifizieren kann. Bei der Arbeit mit Milliarden oder Billionen von Parametern werden Algorithmen zur Rückpropagierung eingesetzt, um den Prozess zu automatisieren. Trotz allem ist das Training ein lang andauernder Prozess, den Verarbeitungslatenzen, die im zugrunde liegenden physikalischen Netzwerk des Datencenters auftreten können, verzögern oder unterbrechen können. Dieses Phänomen nennt man Tail-Latenz und es kann dazu führen, dass wesentlich mehr Zeit und Kosten in den Trainingsprozess investiert werden müssen, sofern das Datencenter-Netzwerk nicht über ein entsprechendes Design verfügt.
Im nächsten Blogbeitrag geht es darum, wie Unternehmen diese grundlegenden LLMs nutzen können, um ihre eigenen benutzerdefinierten KI-Anwendungen bereitzustellen, die aus privaten Datencentern stammen.
Sie wollen erfahren, wie andere Unternehmen die Infrastruktur aufbauen, um mit diesen Herausforderungen umzugehen? Besuchen Sie unseren virtuellen Event Seize the AI Moment für Einblicke von AMD, Intel, Meta, PayPal und vielen mehr.


